这是本人首次参加数学建模竞赛,最终获得了全校二等奖的好成绩,获奖链接:https://mp.weixin.qq.com/s/w1W8XwT2oHP4LlE9SSGCBw,本次获奖让我备受鼓舞,下次准备继续冲击2020年的全国竞赛。
原文标题是《基于多推销员问题的地铁线路规划模型及其新构想》,其中"新构想"部分由队友完成,本篇博客主要讲述本人思考和解题的过程,供学习交流。
一、引言
1.1 问题背景
P 同学计划对广州地铁的多个中转站进行实地调查,内容包括记录各站点的屏蔽门编号以及不同线路间切换电梯与屏蔽门的相对位置。由于该类信息在公开平台无法获取,只能通过亲自到访各中转站进行实地观察。
调查活动受以下条件约束:
- 起终点灵活选择:出发地和返回地均可选择中大站或鹭江站;
- 排除特定线路:不调查9号线、14号线、21号线及13号线相关的中转站;
- APM线无需单独调查:APM线在地铁站内的换乘与出站模式与普通线路相近,故不纳入调查范围;
- 每次到站均需出站观察:P同学到达每个中转站后,均需出站观察后再重新进站;
- 同站第二次经过可不下车:若两次经过同一中转站,第二次可不下车直接通过。
1.2 问题简述
问题一:如何选择一条调查路线,使得完成全部27个中转站调查的总耗时最低,要求从中大站或鹭江站出发并最终返回同一站点(单天方案)。
问题二:P同学认为集中于一天完成全部调查在体力上不可接受,计划将调查分5天进行。每天从起点出发完成该天调查后返回终点,如何规划每天的路线,使得5天总耗时最低。
问题三:在问题二路线方案确定的前提下,P同学的舅舅与舅母每天在广州地铁8号线沿线各中转站上班,上班地点随机且上下班时间均为全天。计算P同学与他们单人相遇的总次数期望、相遇次数总和的期望与方差。
二、前置知识
本章介绍后续章节中将直接引用的数学原理,主要涉及图论基础、最短路径算法、组合优化及概率论的相关知识。这些内容在大学本科离散数学课和概率论课程中已有系统讨论,本处仅作概念界定与结果引用,不再赘述严格证明。
2.1 图论基础
(1) 有权无向图的定义
图 G(V, E, W) 由三个要素构成:节点集合 V = {v₁, v₂, …, vₙ},边集合 E ⊆ V × V,以及权重函数 W: E → ℝ⁺。若对于任意节点对 (vᵢ, vⱼ) ∈ E 均有 (vⱼ, vᵢ) ∈ E,且权重满足 W(vᵢ, vⱼ) = W(vⱼ, vᵢ),则称 G 为有权无向图。
地铁网络经建模后恰好构成有权无向图:各中转站为节点,站点间的地铁线路段为边,地铁运行时长为边权重。
(2) 邻接矩阵与可达性
设图 G 有 n 个节点,定义邻接矩阵 A 为 n × n 矩阵,其中:
$$A_{ij} = \begin{cases} W(v_i, v_j), & \text{若 } (v_i, v_j) \in E \ 0, & \text{若 } i = j \ \infty, & \text{其他} \end{cases}$$
邻接矩阵描述了图中各节点间的直接连通性与权重。对于不相邻的节点对,其对应矩阵元素为无穷大,表示无法直接到达。
(3) 最短路径问题
最短路径问题要求找到从指定起点到终点的一条路径,使得路径上所有边权重之和最小。在有权无向图中,该问题存在多种经典求解算法,适用于不同场景。
2.2 最佳哈密尔顿圈与最佳推销员路径
(1) 基本定义与区别
最佳哈密尔顿圈(Best Hamiltonian Cycle):从一个节点出发,经过图中所有节点恰好一次后返回起点,形成一条哈密尔顿回路,使总边权最小。
最佳推销员路径(Best Salesman Route):从一个节点出发,经过图中所有节点至少一次后返回起点,使总边权最小。两者的区别在于节点访问次数的要求不同。
(2) 三角不等式与完备图转化条件
并非所有图都存在哈密尔顿圈。图论指出:当且仅当图为完备图(任意两节点间均有边相连)时,哈密尔顿圈才必然存在。
然而,最佳推销员路径问题不要求图完备。在求解时,可通过算法将不完备图转化为完备图,若新增边的权重满足三角不等式:
$$W_{ik} \leq W_{ij} + W_{jk}$$
则在该完备图中求得的最佳哈密尔顿圈权值,等同于原不完备图中最佳推销员路径的权值。这一转化为后续求解提供了基础。
2.3 Floyd 算法
(1) 算法原理
Floyd 算法(又称 Floyd-Warshall 算法)用于求解图中任意两节点间的最短路径。其核心思想为动态规划:
设 $d^{(k)}_{ij}$ 表示从节点 vᵢ 到节点 vⱼ 的最短路径,且该路径的中间节点编号不超过 k。递推关系为:
$$\min_{k} d_{ij}^{(k)} = \min \left( d_{ij}^{(k-1)}, d_{ik}^{(k-1)} + d_{kj}^{(k-1)} \right)$$
初始时 $d^{(0)}_{ij}$ 即为邻接矩阵中的权重值。通过依次引入节点 1, 2, …, n 作为中转点,逐步更新最短路径矩阵,直至得到所有节点对之间的最短路径。
(2) 在完备图转化中的应用
Floyd 算法的直接应用是求最短路径,但本题中另有妙用:利用其结果补全不完备图。
将原图的邻接矩阵作为输入,求得两节点间的最短路径长度后,以该长度作为新边权重加入图中,即可将不完备图转化为完备图。由于最短路径本身必然满足三角不等式,转化后的完备图满足最佳哈密尔顿圈与最佳推销员路径等价的前提条件。
2.4 二边逐次修正算法(2-opt)
(1) 算法原理
2-opt 是求解最佳哈密尔顿圈的一种局部搜索算法。给定一条初始回路,若某两条非相邻边 (vᵢ, vᵢ₊₁) 和 (vⱼ, vⱼ₊₁)(i < j,且不相邻)满足:
$$W_{i,j} + W_{i+1,j+1} < W_{i,i+1} + W_{j,j+1}$$
则将这两条边替换为 (vᵢ, vⱼ) 和 (vᵢ₊₁, vⱼ₊₁),可使回路总权值减少。替换后回路的节点访问顺序发生变化,形象地称为"翻转"。
(2) 迭代过程与收敛条件
算法迭代步骤如下:
- 任意给定一条哈密尔顿回路作为初始解;
- 遍历所有满足条件的边对 (i, j),检查上式是否成立;
- 若成立,执行替换,得到一条更优回路;
- 重复步骤2-3,直至遍历全图后不存在可替换的边对。
由于每次替换严格降低总权值,而权值下界有限,算法必在有限次迭代后收敛,得到局部最优解——即 2-opt 意义下的最佳哈密尔顿圈。
2.5 最小生成树与 Prim 算法
(1) 最小生成树定义
设连通图 G(V, E, W),生成树 T 为 G 的一个子图,包含全部节点 |V| 个节点和 |V|−1 条边,且不形成环。最小生成树(Minimum Spanning Tree, MST) 是所有生成树中边权之和最小的那一棵。
最小生成树具有两个关键性质:(1)包含全部节点;(2)边权之和最小。这使其成为网络划分问题的有力工具。
(2) Prim 算法步骤
Prim 算法是构建最小生成树的经典算法,属于贪心策略,步骤如下:
- 任意选择一个起始节点,将其加入树中;
- 重复以下步骤直至所有节点均已加入:
- 在所有连接已加入节点与未加入节点的边中,选择权重最小的一条;
- 将该边及其未加入端点加入生成树;
- 最终得到包含全部节点、恰好 n−1 条边、总权值最小的生成树。
2.6 概率期望基础
(1) 离散型随机变量期望
设离散型随机变量 X 取值 x₁, x₂, …, xₙ,对应概率为 p₁, p₂, …, pₙ,则 X 的数学期望为:
$$E(X) = \sum_{k=1}^{n} x_k \cdot p_k$$
期望描述了随机变量在重复试验中的平均取值。
(2) 方差的定义与计算
方差用于衡量随机变量取值与其期望的偏离程度,定义为:
$$\text{Var}(X) = E\left[(X - E(X))^2\right] = E(X^2) - [E(X)]^2$$
对于离散型随机变量:
$$\text{Var}(X) = \sum_{k=1}^{n} (x_k - E(X))^2 \cdot p_k$$
三、问题分析与求解思路
3.1 数据来源
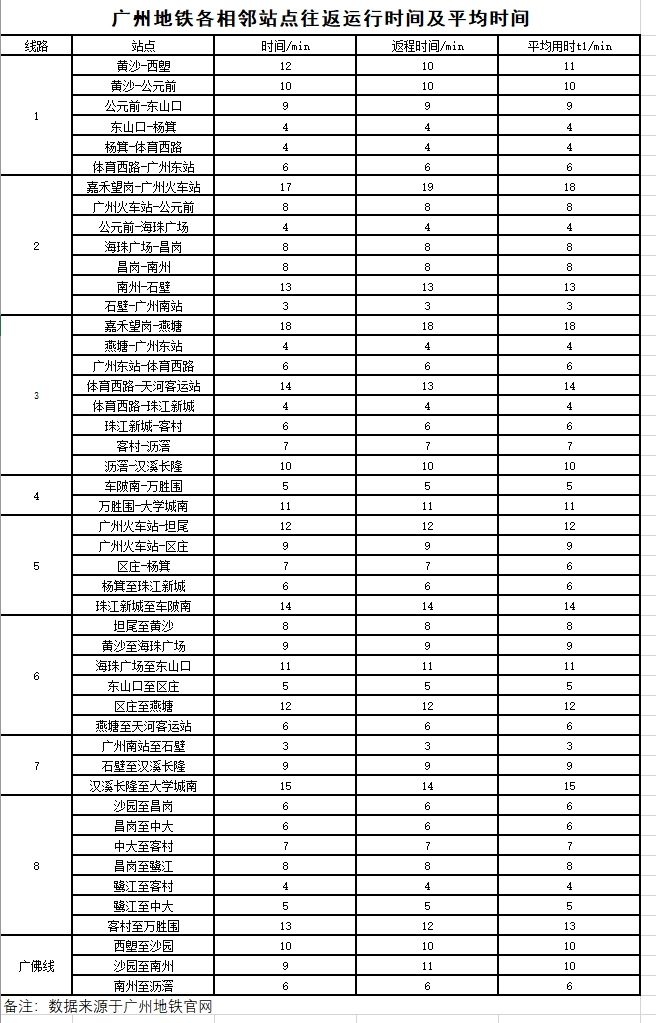
本文所涉及的地铁在各中转站点间的运行时间数据,全部来源于广州地铁官方网站(http://www.gzmtr.com/)。原始数据包含各相邻站点间的往返运行时间,本文中取往返时间的算术平均值作为各边权重用于建模。
3.2 模型假设
(1)假设 P 同学在地铁中转站进行换乘(非调查时间)时不花费时间。
(2)假设在地铁在每两个中转站之间往返花费时间相同(实际花费时间也基本相同)。
(3)地铁运行为理想状态,不会发生延误或发生故障等不可抗力因素。
3.3 符号定义
| 符号 | 含义 | 符号 | 含义 | |
|---|---|---|---|---|
| $t_1$ | 地铁在线路上运行的总时间 | $W_{ij}$ | 任意两个站点间的权重 | |
| $t_2$ | 调查各个中转站点的总时间 | $G$ | 图 | |
| $t$ | P 同学在线路上所花的总时间 | $G_i$ | 子图 | |
| $t_i$ | 任意子图线路所花总时间 | $E_i$ | 第 i 天与舅舅/舅母相遇次数的期望 | |
| $t_{1i}$ | 地铁在任意一个子图线路上运行的总时间 | $P_j$ | 舅舅舅母在第 j 个站点工作的概率 | |
| $t_{2i}$ | 调查任意一个子图上各个中转站点的总时间 | $Q_{ij}$ | 第 i 天在第 j 个站点相遇次数的权重 | |
| $V$ | 所有节点的集合 | $T$ | 所有子图线路所花总时间 | |
| $E$ | 所有线路(边)的集合 |
3.4 求解原理与方法
问题一:最佳哈密尔顿圈等价于最短哈密尔顿回路,对应方法为 Floyd 算法补全完备图并结合 2-opt 迭代求解。
问题二:多旅行商路径分解为区域划分与子回路优化,对应方法为 Prim 算法生成最小生成树,划分区域后对每区域独立求解最佳 H 圈。
问题三:相遇次数为带权重的离散型随机变量,对应方法为建立权重矩阵 $Q_{ij}$,计算期望 $E_i = \sum_j P_j \cdot Q_{ij}$ 及其方差。
四、模型建立与求解
4.1 问题一:单天最佳调查路线
4.1.1 问题转化
总时间 $t$ 由两部分构成:
$$t = t_1 + t_2$$
其中 $t_2$ 为各站点调查时间之和,各站点的调查耗时可在实地获取后直接累加,数值固定。$t_1$ 为地铁在线路上运行的总时间,取决于所选路线,是需要最小化的目标。
因此,最小化 $t$ 等价于最小化地铁运行时间 $t_1$。
该问题在图论中对应最佳推销员路径问题(Best Salesman Route Problem):从起点出发,经过所有节点至少一次后返回终点,使总边权最小。与经典哈密尔顿圈问题的区别在于,每个节点只需访问至少一次而非恰好一次。
4.1.2 图的简化与权重定义
将广州地铁网络抽象为有权无向图 G(V, E, W):
- 节点集合 V:27个需调查的中转站,各站点编号及对应名称如下表所示:
| 编号 | 站名 | 调查耗时(min) | 编号 | 站名 | 调查耗时(min) | |
|---|---|---|---|---|---|---|
| 1 | 中大 | — | 15 | 车陂南 | 6 | |
| 2 | 广州火车站 | 8 | 16 | 西塱 | 6 | |
| 3 | 燕塘 | 6 | 17 | 沙园 | 6 | |
| 4 | 天河客运站 | 8 | 18 | 昌岗 | 6 | |
| 5 | 广州东站 | 10 | 19 | 客村 | 8 | |
| 6 | 区庄 | 8 | 20 | 万胜围 | 8 | |
| 7 | 公元前 | 8 | 21 | 南洲 | 6 | |
| 8 | 东山口 | 8 | 22 | 沥滘 | 8 | |
| 9 | 杨箕 | 8 | 23 | 大学城南 | 6 | |
| 10 | 体育西路 | 15 | 24 | 石壁 | 6 | |
| 11 | 坦尾 | 6 | 25 | 汉溪长隆 | 6 | |
| 12 | 黄沙 | 6 | 26 | 广州南站 | 8 | |
| 13 | 海珠广场 | 8 | 27 | 嘉禾望岗 | 6 | |
| 14 | 珠江新城 | 10 | — | — | — |
- 边集合 E:相邻中转站之间的地铁线路段。若两站点间可一站直达,则两节点之间存在一条边相连;
- 权重 W:各站点间地铁运行的耗时。具体而言,记相邻两站点间的地铁运行时间为 $t$(即该边权重),则 $W_{ij} = t$。若两站点之间不能一站直达(即无可直达边),则 $W_{ij} = \infty$。
由于原地铁网络并非任意两节点间均有直达边,原图 G(V, E, W) 为非完备图,无法直接在其上求解最佳哈密尔顿圈。
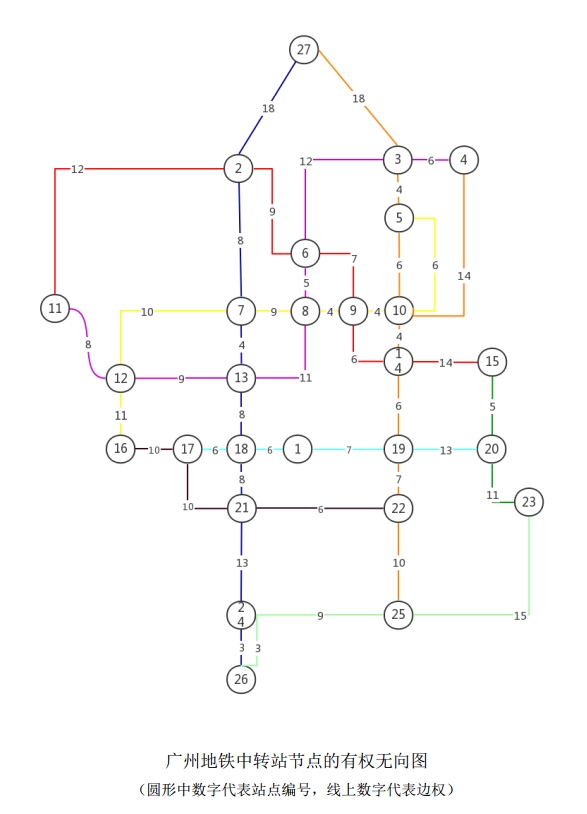
4.1.3 Floyd 算法补全完备图
Floyd 算法(Floyd-Warshall Algorithm)用于求解任意两节点间的最短路径,是动态规划思想的典型应用。
其核心递推关系为:依次引入节点 k 作为中转点,判断从节点 i 到节点 j 经由 k 的路径是否比当前已知最短路径更短,若是则更新最短路径长度。数学表达为:
$$\min_{k} d_{ij}^{(k)} = \min \left( d_{ij}^{(k-1)}, d_{ik}^{(k-1)} + d_{kj}^{(k-1)} \right)$$
将原图的邻接矩阵作为输入执行 Floyd 算法,得到任意两节点间的最短路径长度,以此作为新边权重加入图中,可将非完备图 G 转化为完备图 G’。
由于最短路径本身必满足三角不等式 $W_{ik} \leq W_{ij} + W_{jk}$,在完备图 G’ 中求得的最佳哈密尔顿圈权值,即为原非完备图 G 中最佳推销员路径的最小权值。这一步是整个求解过程的关键过渡。
以下为 Floyd 算法的 MATLAB 实现代码:
function [path,road]=floyd(a)
n=size(a,1);
path=a;
for i = 1:n
for j = 1:n
road(i,j) = j;
end
end
for k=1:n
for i=1:n
for j=1:n
if path(i,j)>path(i,k)+path(k,j)
path(i,j)=path(i,k)+path(k,j);
road(i,j)=road(i,k);
end
end
end
end
4.1.4 最佳哈密尔顿圈求解
在完备图 G’ 上,采用 二边逐次修正算法(2-opt) 逐步优化初始回路。
给定一条哈密尔顿回路,遍历任意两条非相邻边 $(v_i, v_{i+1})$ 和 $(v_j, v_{j+1})$($i < j$ 且两对边不相邻)。若满足:
$$W_{i,j} + W_{i+1,j+1} < W_{i,i+1} + W_{j,j+1}$$
则以边 $(v_i, v_j)$ 和 $(v_{i+1}, v_{j+1})$ 替换原两条边,使回路总权值减少。每完成一次替换称为一次"2-opt 翻转"。重复遍历与替换,直至遍历全图后不存在可改进的边对,算法收敛,得到局部最优的哈密尔顿回路,即为所求最佳 H 圈。 重复遍历与替换,直至遍历全图后不存在可改进的边对,算法收敛,得到局部最优的哈密尔顿回路,即为所求最佳 H 圈。
以下为 2-opt 算法的 MATLAB 实现代码:
function [b,s] = h(e)
n=size(e);
for i=2:n-2
for j = i+1:n-2
if e(i,j)+e(i+1,j+1)<e(i,i+1)+e(j,j+1)
a=horzcat(e(:,1:i),e(:,j:-1:i+1),e(:,j+1:n));
b=vertcat(a(1:i,:),a(j:-1:i+1,:),a(j+1:n,:));
e=b;
end
end
end
s=0;
for i=2:n-2
s=s+e(i,i+1);
end
4.1.5 两种方案对比
以下为问题一求解的完整 MATLAB 程序代码:
clc
clear
%打开中大作为起点终点的矩阵,即可得到问题一的方案一的解
%打开鹭江作为起点终点的矩阵,即可得到问题一的方案二的解
%各站点检查的时间
t=[0 6 8 6 8 10 8 8 8 8 15 6 6 8 10 6 6 6 6 8 8 6 8 6 6 6 8];
% 定义中大上落站的领接矩阵
a=[0 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 6 7 inf inf inf inf inf inf inf inf;
0 0 inf inf inf 9 8 inf inf inf 12 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 18;
0 0 0 6 4 12 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 18;
0 0 0 0 inf inf inf inf inf 14 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 inf inf inf inf 6 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 inf 5 7 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 9 inf inf inf 10 4 inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 4 inf inf inf 11 inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 4 inf inf inf 6 inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 inf inf inf 4 inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 8 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 9 inf inf 11 inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf inf inf 8 inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 14 inf inf inf 6 inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf inf inf 5 inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 inf inf 10 inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 inf 8 inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 13 inf 7 inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf 11 inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 inf 13 inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf 10 inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf 15 inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 3 inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0];
%定义鹭江上落站的邻接矩阵
% a=[0 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 8 4 inf inf inf inf inf inf inf inf;
% 0 0 inf inf inf 9 8 inf inf inf 12 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 18;
% 0 0 0 6 4 12 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 18;
% 0 0 0 0 inf inf inf inf inf 14 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 inf inf inf inf 6 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 inf 5 7 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 9 inf inf inf 10 4 inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 4 inf inf inf 11 inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 4 inf inf inf 6 inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 inf inf inf 4 inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 8 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 9 inf inf 11 inf inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf inf inf 8 inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 14 inf inf inf 6 inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf inf inf 5 inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 inf inf inf inf inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 inf inf 10 inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 inf 8 inf inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 13 inf 7 inf inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf 11 inf inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 inf 13 inf inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf 10 inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf 15 inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 3 inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf;
% 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0];
a=a'+a;
[path,road]=floyd(a);
% for i=1:27
% for j=1:27
% displaypath(path,road,i,j)
% end
% end
e=path;
[r,~]=size(e);
e(:,r+1)=e(:,1);
e(r+1,:)=e(1,:);
c(1,1:r+1)=1:r+1;
c(r+1)=1;
e=[c;e;c];
c=zeros(r+3,1);
e=[c,e,c];
[b,s]=h(e);
try_number=0;
while 1
try
[b,s]=h(b);
try_number=try_number+1;
catch
break
end
end
route=b(1,:);
route=route(1,2:29);
disp(route)
t=sum(t);
s=s+t;
fprintf('s='),disp(s)
方案一:以中大站(编号 $V_1$)为起点和终点,构建 27×27 维邻接矩阵并代入 Floyd 算法补全完备图,再以 2-opt 迭代求解最佳 H 圈。
初始最佳 H 圈路线如下:
$$V_1 \rightarrow V_{18} \rightarrow V_{17} \rightarrow V_{16} \rightarrow V_{12} \rightarrow V_{11} \rightarrow V_{12} \rightarrow V_{13} \rightarrow V_{7} \rightarrow V_{2} \rightarrow V_{6} \rightarrow V_{8} \rightarrow V_{9} \rightarrow V_{10} \rightarrow V_{5} \rightarrow V_{3} \rightarrow V_{27} \rightarrow V_{3} \rightarrow V_{4} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{15} \rightarrow V_{20} \rightarrow V_{23} \rightarrow V_{25} \rightarrow V_{24} \rightarrow V_{26} \rightarrow V_{24} \rightarrow V_{21} \rightarrow V_{22} \rightarrow V_{19} \rightarrow V_{1}$$
初始总时长 450 min。
方案一优化:分析路线可知,P 同学去程从中大前往昌岗,最后经客村站返回中大站。因此可令 P 同学提前在鹭江站下车并结束调查,从而省去鹭江站至中大站的行驶时间 5 min。优化后终点调整为鹭江站(编号 $V_0$),最终时长 445 min。
方案二:以鹭江站(编号 $V_0$)为起点和终点,同理构建邻接矩阵并通过 Floyd + 2-opt 求解,最佳 H 圈路线总时长 443 min。经检验,该方案的起点终点设置使得首站与末站均为客村站,已达到该问题结构下的最优,无需进一步优化。
4.1.6 结论
方案二优于方案一,选取鹭江站作为出发点和终止点。
最优路线为:
$$V_0 \rightarrow V_{19} \rightarrow V_{22} \rightarrow V_{21} \rightarrow V_{24} \rightarrow V_{26} \rightarrow V_{24} \rightarrow V_{25} \rightarrow V_{23} \rightarrow V_{20} \rightarrow V_{15} \rightarrow V_{14} \rightarrow V_{9} \rightarrow V_{6} \rightarrow V_{8} \rightarrow V_{7} \rightarrow V_{13} \rightarrow V_{18} \rightarrow V_{17} \rightarrow V_{16} \rightarrow V_{12} \rightarrow V_{11} \rightarrow V_{2} \rightarrow V_{27} \rightarrow V_{3} \rightarrow V_{4} \rightarrow V_{3} \rightarrow V_{5} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{19} \rightarrow V_{1} \rightarrow V_{0}$$
总用时:443 min
4.2 问题二:分五天调查路线规划
4.2.1 问题分析
问题二要求将全部27个中转站的调查任务分5天完成,每天从起点出发完成该天调查后返回终点。五天的路线相互独立,分别对应原图 G 的五个子图 $G_i(i=1,2,3,4,5)$。目标函数为:
$$\min \sum_{i=1}^{5} t_i$$
其中 $t_i$ 为第 i 个子图的总耗时,且满足 $t_i = t_{1i} + t_{2i}$($t_{1i}$ 为地铁运行耗时,$t_{2i}$ 为站点调查耗时)。
此外,P 同学提出"集中时间调查太累",因此在总耗时尽可能低的前提下,还需考虑各天工作量的均衡程度。引入均衡系数 $\lambda$ 衡量各天路线的均衡性:
$$\lambda = \frac{W_{\max} - W_{\min}}{W_{\max}}$$
其中 $W_{\max}$ 和 $W_{\min}$ 分别为五天内各天最佳 H 圈边权值的最大值与最小值。$\lambda$ 越小,表示五天工作量分布越均衡。
该问题在图论中对应多旅行商路线问题(m-Traveling Salesman Problem, m-TSP):m 个人在总图上行走,要求到达每个节点至少一次且总距离最短。
4.2.2 最小生成树区域划分
多旅行商路线问题的核心难点在于如何将总图合理划分为 m 个连通子图。若划分不当,即使各子图内部优化良好,整体效果也可能不佳。
本题采用最小生成树(Minimum Spanning Tree, MST) 进行区域划分。设连通图 G(V, E, W),生成树 T 为 G 的子图,包含全部 |V| 个节点和 |V|−1 条边,且不形成环。最小生成树是所有生成树中边权之和最小的那一棵。
将原图 G 的邻接矩阵代入 Prim 算法 生成最小生成树,其核心思想为:从任意节点出发,每次选择一条权重最小且不形成环的边扩展生成树,直至所有节点均已加入。
以下为 Prim 算法生成最小生成树的 MATLAB 实现代码:
clear
clc
a=[0 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 6 7 inf inf inf inf inf inf inf inf;
0 0 inf inf inf 9 8 inf inf inf 12 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 18;
0 0 0 6 4 12 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf 18;
0 0 0 0 inf inf inf inf inf 14 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 inf inf inf inf 6 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 inf 5 7 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 9 inf inf inf 10 4 inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 4 inf inf inf 11 inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 4 inf inf inf 6 inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 inf inf inf 4 inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 8 inf inf inf inf inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 9 inf inf 11 inf inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf inf inf 8 inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 14 inf inf inf 6 inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf inf inf 5 inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 10 inf inf inf inf inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 inf inf 10 inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 inf 8 inf inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 13 inf 7 inf inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf 11 inf inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 6 inf 13 inf inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf 10 inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf 15 inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 3 inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 inf;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0];
a=a+a';
a(a==0)=inf;
result=[];
p=1;
tb=2:length(a);
while size(result,2)~=length(a)-1
temp=a(p,tb);
temp=temp(:);
d=min(temp);
[jb,kb]=find(a(p,tb)==d,1);
j=p(jb);
k=tb(kb);
result = [result,[j;k;d]];
p=[p,k];
tb(find(tb==k))=[];
end
result;
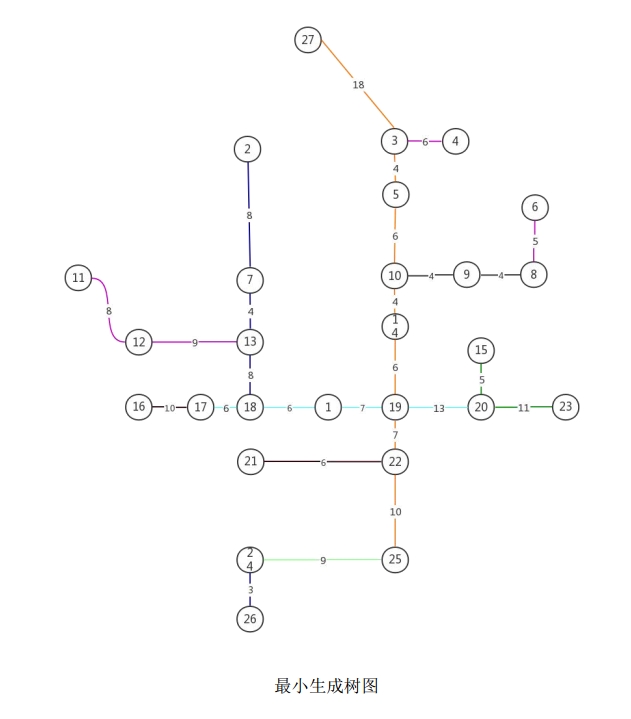
利用最小生成树进行划分的依据在于:最小生成树的边权值即为相邻两节点的边权之和最小化,能够到达所有节点而不形成环。由于这两个性质能够很好地支撑区域划分,因此采用最小生成树分解的方法来得到5个子图 $G_i$。
划分原则如下:
(1)分解点选在1号站(中大站,编号 $V_1$)或其邻近站点,以便各天均能从起点出发完成调查后返回。
(2)各子图内部须为连通图,确保调查路线在区域内形成有效回路。
(3)各子图应容易形成环形或接近环形的结构,便于后续求解最佳 H 圈。
基于上述原则,将最小生成树划分为5个区域,划分结果对应的站点分配如下:
| 区域 | 站点编号 | 调查总时长 $t_{2i}$(min) |
|---|---|---|
| 第1天 | 15,19,20,23 | 32 |
| 第2天 | 6,8,9,10,14 | 42 |
| 第3天 | 3,4,5,27 | 30 |
| 第4天 | 21,22,24,25,26 | 32 |
| 第5天 | 2,7,11,12,13,16,18 | 59 |
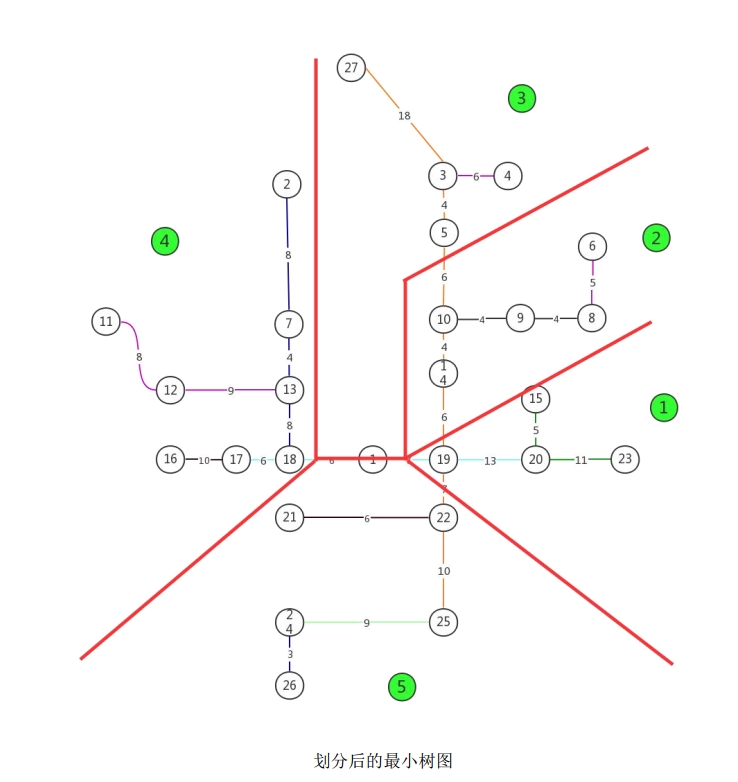
4.2.3 各区域最佳 H 圈求解
对划分后的每个子图 $G_i$,采用与问题一相同的求解方法:构建各子图的邻接矩阵,通过 Floyd 算法补全完备图,再以 2-opt 迭代求解最佳 H 圈。
以下为问题二求解的完整 MATLAB 程序代码:
t=[0 6 8 6 8 10 8 8 8 8 15 6 6 8 10 6 6 6 6 8 8 6 8 6 6 6 8];
% 方案一
a=[0 inf 7 inf inf;
0 0 inf 5 inf;
0 0 0 13 inf;
0 0 0 0 11;
0 0 0 0 0];
a=a'+a;
[path,road]=floyd(a);
e=path;
[r,~]=size(e);
e(:,r+1)=e(:,1);
e(r+1,:)=e(1,:);
c=[1 15 19 20 23 1];
e=[c;e;c];
c=zeros(r+3,1);
e=[c,e,c];
[b1,s1]=h(e);
t1=t(19)+t(15)+t(20)+t(23);
s1=s1+t1;
a=[0 inf inf inf inf inf 7;
0 0 5 7 inf inf inf;
0 0 0 4 inf inf inf;
0 0 0 0 4 6 inf;
0 0 0 0 0 4 inf;
0 0 0 0 0 0 8;
0 0 0 0 0 0 0];
a=a'+a;
[path,road]=floyd(a);
e=path;
[r,~]=size(e);
e(:,r+1)=e(:,1);
e(r+1,:)=e(1,:);
c=[1 6 8 9 10 14 19 1];
e=[c;e;c];
c=zeros(r+3,1);
e=[c,e,c];
n=size(e);
s2=0;
for i=2:n-2
s2=s2+e(i,i+1);
end
b2=e;
t2=t(6)+t(8)+t(9)+t(10)+t(14);
s2=s2+t2;
a=[0 inf inf inf inf inf 7 inf;
0 0 6 4 inf inf inf 18;
0 0 0 inf 14 inf inf inf;
0 0 0 0 6 inf inf inf;
0 0 0 0 0 4 inf inf;
0 0 0 0 0 0 6 inf;
0 0 0 0 0 0 0 inf;
0 0 0 0 0 0 0 0];
a=a'+a;
[path,road]=floyd(a);
e=path;
[r,~]=size(e);
e(:,r+1)=e(:,1);
e(r+1,:)=e(1,:);
c=[1 3 4 5 10 14 19 27 1];
e=[c;e;c];
c=zeros(r+3,1);
e=[c,e,c];
[b3,s3]=h(e);
t3=t(3)+t(4)+t(5)+t(27);
s3=s3+t3;
a=[0 7 inf inf inf inf inf;
0 0 10 inf inf inf inf;
0 0 0 6 13 inf inf;
0 0 0 0 inf 10 inf;
0 0 0 0 0 9 8;
0 0 0 0 0 0 inf;
0 0 0 0 0 0 0];
a=a'+a;
[path,road]=floyd(a);
e=path;
[r,~]=size(e);
e(:,r+1)=e(:,1);
e(r+1,:)=e(1,:);
c=[1 19 21 22 24 25 26 1];
e=[c;e;c];
c=zeros(r+3,1);
e=[c,e,c];
[b4,s4]=h(e);
t4=sum(t(21:22))+sum(t(24:26));
s4=s4+t4;
a=[0 inf inf inf inf inf inf inf 6;
0 0 8 12 inf inf inf inf inf;
0 0 0 inf 10 4 inf inf inf;
0 0 0 0 8 inf inf inf inf;
0 0 0 0 0 9 11 inf inf;
0 0 0 0 0 0 inf inf 8;
0 0 0 0 0 0 0 10 inf;
0 0 0 0 0 0 0 0 6;
0 0 0 0 0 0 0 0 0];
a=a'+a;
[path,road]=floyd(a);
e=path;
[r,~]=size(e);
e(:,r+1)=e(:,1);
e(r+1,:)=e(1,:);
c=[1 2 7 11 12 13 16 17 18 1];
e=[c;e;c];
c=zeros(r+3,1);
e=[c,e,c];
[b5,s5]=h(e);
t5=t(2)+t(7)+sum(t(11:13))+sum(t(16:18));
s5=s5+t5;
各区域独立求解后,得到的初始方案结果如下:
| 区域 | 路线 | 地铁运行 $t_{1i}$(min) | 调查 $t_{2i}$(min) | 区域总耗时 $t_i$(min) | 均衡值 $\lambda$(%) |
| 区域 | 路线 | 地铁运行 $t_{1i}$(min) | 调查 $t_{2i}$(min) | 区域总耗时 $t_i$(min) | 总耗时 $T$(min) | 均衡值 $\lambda$(%) |
|---|---|---|---|---|---|---|
| 第1天 | $V_1 \rightarrow V_{19} \rightarrow V_{20} \rightarrow V_{15} \rightarrow V_{20} \rightarrow V_{23} \rightarrow V_{20} \rightarrow V_{19} \rightarrow V_1$ | 72 | 32 | 104 | 594 | 26.09 |
| 第2天 | $V_1 \rightarrow V_{19} \rightarrow V_{14} \rightarrow V_{9} \rightarrow V_{6} \rightarrow V_{8} \rightarrow V_{9} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{19} \rightarrow V_1$ | 60 | 42 | 102 | — | — |
| 第3天 | $V_1 \rightarrow V_{19} \rightarrow V_{14} \rightarrow V_{10} \rightarrow V_{5} \rightarrow V_{3} \rightarrow V_{27} \rightarrow V_{3} \rightarrow V_{4} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{19} \rightarrow V_1$ | 100 | 30 | 130 | — | — |
| 第4天 | $V_1 \rightarrow V_{19} \rightarrow V_{22} \rightarrow V_{21} \rightarrow V_{22} \rightarrow V_{25} \rightarrow V_{24} \rightarrow V_{26} \rightarrow V_{24} \rightarrow V_{21} \rightarrow V_{18} \rightarrow V_1$ | 88 | 32 | 120 | — | — |
| 第5天 | $V_1 \rightarrow V_{18} \rightarrow V_{13} \rightarrow V_{7} \rightarrow V_{2} \rightarrow V_{11} \rightarrow V_{12} \rightarrow V_{16} \rightarrow V_{17} \rightarrow V_{18} \rightarrow V_1$ | 79 | 59 | 138 | — | — |
4.2.4 优化过程
第一轮优化——起点终点调整:将各天的起点和终点统一调整为鹭江站(编号 $V_0$),使各天调查的起点和终点均从鹭江站出发和返回。结果如下:
| 区域 | 路线 | 地铁运行 $t_{1i}$(min) | 调查 $t_{2i}$(min) | 区域总耗时 $t_i$(min) | 总耗时 $T$(min) | 均衡值 $\lambda$(%) |
|---|---|---|---|---|---|---|
| 第1天 | $V_0 \rightarrow V_{19} \rightarrow V_{20} \rightarrow V_{15} \rightarrow V_{20} \rightarrow V_{23} \rightarrow V_{20} \rightarrow V_{19} \rightarrow V_0$ | 62 | 32 | 94 | 559 | 33.33 |
| 第2天 | $V_0 \rightarrow V_{19} \rightarrow V_{14} \rightarrow V_{9} \rightarrow V_{6} \rightarrow V_{8} \rightarrow V_{9} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{19} \rightarrow V_0$ | 50 | 42 | 92 | — | — |
| 第3天 | $V_0 \rightarrow V_{19} \rightarrow V_{14} \rightarrow V_{10} \rightarrow V_{5} \rightarrow V_{3} \rightarrow V_{27} \rightarrow V_{3} \rightarrow V_{4} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{19} \rightarrow V_0$ | 90 | 30 | 120 | — | — |
| 第4天 | $V_0 \rightarrow V_{19} \rightarrow V_{22} \rightarrow V_{21} \rightarrow V_{22} \rightarrow V_{25} \rightarrow V_{24} \rightarrow V_{26} \rightarrow V_{24} \rightarrow V_{21} \rightarrow V_{18} \rightarrow V_1$ | 83 | 32 | 115 | — | — |
| 第5天 | $V_1 \rightarrow V_{18} \rightarrow V_{13} \rightarrow V_{7} \rightarrow V_{2} \rightarrow V_{11} \rightarrow V_{12} \rightarrow V_{16} \rightarrow V_{17} \rightarrow V_{18} \rightarrow V_1$ | 79 | 59 | 138 | — | — |
优化后总耗时由 594 min 降至 559 min,均衡值 $\lambda$ 由 26.09% 升至 33.33%,总耗时减少且各天工作量分布更加均衡。
第二轮微调——站点跨区调整:在第一轮优化基础上,尝试将部分站点跨区调整以进一步降低均衡值 $\lambda$,并比较总耗时的变化。
优化方案一:将16、17、18号站点由第5天调整至第1天,调整后第1天总耗时增加65 min,第5天总耗时减少28 min,但五天总耗时合计反而增加,总耗时与均衡值均劣于原方案,不予采用。
优化方案二:将5号站点由第3天调整至第2天,结果同样导致总耗时增加,不予采用。
经两轮优化与比较,以时间最短为原则,最终确定第一轮优化方案为最优方案。
4.2.5 最终方案
经上述优化过程,确定问题二最终方案如下:
| 区域 | 路线 | 地铁运行 $t_{1i}$(min) | 调查 $t_{2i}$(min) | 区域总耗时 $t_i$(min) | 总耗时 $T$(min) | 均衡值 $\lambda$(%) |
|---|---|---|---|---|---|---|
| 第1天 | $V_0 \rightarrow V_{19} \rightarrow V_{20} \rightarrow V_{15} \rightarrow V_{20} \rightarrow V_{23} \rightarrow V_{20} \rightarrow V_{19} \rightarrow V_0$ | 62 | 32 | 94 | 559 | 33.33 |
| 第2天 | $V_0 \rightarrow V_{19} \rightarrow V_{14} \rightarrow V_{9} \rightarrow V_{6} \rightarrow V_{8} \rightarrow V_{9} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{19} \rightarrow V_0$ | 50 | 42 | 92 | — | — |
| 第3天 | $V_0 \rightarrow V_{19} \rightarrow V_{14} \rightarrow V_{10} \rightarrow V_{5} \rightarrow V_{3} \rightarrow V_{27} \rightarrow V_{3} \rightarrow V_{4} \rightarrow V_{10} \rightarrow V_{14} \rightarrow V_{19} \rightarrow V_0$ | 90 | 30 | 120 | — | — |
| 第4天 | $V_0 \rightarrow V_{19} \rightarrow V_{22} \rightarrow V_{21} \rightarrow V_{22} \rightarrow V_{25} \rightarrow V_{24} \rightarrow V_{26} \rightarrow V_{24} \rightarrow V_{21} \rightarrow V_{18} \rightarrow V_1$ | 83 | 32 | 115 | — | — |
| 第5天 | $V_1 \rightarrow V_{18} \rightarrow V_{13} \rightarrow V_{7} \rightarrow V_{2} \rightarrow V_{11} \rightarrow V_{12} \rightarrow V_{16} \rightarrow V_{17} \rightarrow V_{18} \rightarrow V_1$ | 79 | 59 | 138 | — | — |
五天总耗时:559 min | 均衡值 $\lambda$:33.33%
4.3 问题三:相遇期望与方差
4.3.1 问题分析
在问题二最终方案确定的路线基础上,P 同学在5天内经过8号线各中转站的次数已完全确定,其是否与舅舅或舅母相遇,完全取决于舅舅与舅母工作的地点。同时,由于不同的调查线路中,P 同学经过8号线每个中转站的次数有区别,问题可看作两类:
- 问题(a):单人相遇期望问题——P 同学与舅舅(或舅母)单人相遇的期望次数;
- 问题(b):组合相遇期望问题——舅舅与舅母同时考虑时,相遇次数总和的期望与方差。
舅舅、舅母各自每天在8号线各中转站工作的概率相互独立,且每天在各站点工作的概率相等,由此相遇问题可建模为带权重的离散型随机变量期望问题。
相遇权重 $Q_{ij}$ 定义为:第 i 天 P 同学在第 j 个站点的相遇加权次数,综合考虑经过该站点的次数及在该站停留的可能性。
4.3.2 期望公式推导
每天相遇期望的通式为:
$$E_i(x) = \sum_{j} P_j \cdot Q_{ij}$$
其中 $E_i(x)$ 为第 i 天单人相遇次数的期望,$P_j$ 为在第 j 个站点工作的概率,$Q_{ij}$ 为第 i 天在第 j 个站点的相遇权重。
由于每天在各站点工作的概率相等,即 $P_j = \frac{1}{n}$(n 为8号线涉及的中转站个数),因此:
$$E_i(x) = \frac{1}{n} \sum_{j} Q_{ij}$$
4.3.3 问题(a)计算结果
基于问题二确定的路线,建立各天各站点的相遇权重矩阵 $Q_{ij}$,代入上式计算,得到每天单人相遇期望次数如下:
| 天数 | 相遇期望次数 |
|---|---|
| 第一天 | 1.00 |
| 第二天 | 0.50 |
| 第三天 | 0.50 |
| 第四天 | 0.50 |
| 第五天 | 0.75 |
| 总和 | 3.25 |
| 方差 | 0.04 |
单人相遇总次数期望为 3.25 次,方差为 0.04。
4.3.4 问题(b)计算结果
对舅舅和舅母的工作地点使用排列组合分析。设8号线沿线调查涉及的站点按位置编号:A 代表沙园站,B 代表昌岗站,C 代表客村站,D 代表万胜围站。
排列组合得到的相遇权重表如下:
| 舅舅工作地点 | 舅母工作地点 | 第一天 | 第二天 | 第三天 | 第四天 | 第五天 |
|---|---|---|---|---|---|---|
| A | A | 0 | 0 | 0 | 0 | 1 |
| A | B | 0 | 0 | 0 | 1 | 3 |
| A | C | 2 | 2 | 2 | 1 | 1 |
| A | D | 2 | 0 | 0 | 0 | 1 |
| B | A | 0 | 0 | 0 | 1 | 3 |
| B | B | 0 | 0 | 0 | 1 | 2 |
| B | C | 2 | 2 | 2 | 2 | 2 |
| B | D | 2 | 0 | 0 | 1 | 2 |
| C | A | 2 | 2 | 2 | 1 | 1 |
| C | B | 2 | 2 | 2 | 2 | 2 |
| C | C | 2 | 2 | 2 | 1 | 0 |
| C | D | 4 | 2 | 2 | 1 | 0 |
| D | A | 2 | 0 | 0 | 0 | 1 |
| D | B | 2 | 0 | 0 | 1 | 2 |
| D | C | 2 | 2 | 2 | 1 | 0 |
| D | D | 4 | 0 | 0 | 0 | 0 |
根据权重表,结合期望公式,舅舅与舅母每天相遇次数的期望计算如下:
$$E_i = \frac{1}{16} \sum Q_i$$
- 第一天:$E_1 = \frac{2 \times 8 + 4 \times 2 + 2 \times 2}{16} = 1.75$
- 第二天:$E_2 = \frac{2 \times 6 + 2 \times 1}{16} = 0.88$
- 第三天:$E_3 = \frac{2 \times 6 + 2 \times 1}{16} = 0.88$
- 第四天:$E_4 = \frac{1 \times 8 + 2 \times 2 + 1 \times 2}{16} = 0.88$
- 第五天:$E_5 = \frac{1 \times 2 + 2 \times 2 + 3 \times 2 + 1 \times 1 + 2 \times 1}{16} = 0.94$
| 天数 | 相遇期望次数 |
|---|---|
| 第一天 | 1.75 |
| 第二天 | 0.88 |
| 第三天 | 0.88 |
| 第四天 | 0.88 |
| 第五天 | 0.94 |
| 总和期望 | 5.31 |
| 方差 | 0.34 |
五、模型评价与总结
5.1 主要结论
(1)问题一最优路线:以鹭江站为出发点和终止点,最佳调查路线总用时 443 min,为单天完成全部27个中转站调查的最优方案。
(2)问题二最优方案:将27个中转站划分为5个区域并独立求解最佳 H 圈,经起点终点优化后,五天总耗时 559 min,均衡值 $\lambda$ 为 33.33%,各天工作量分配较为均衡。
(3)问题三相遇期望:在问题二路线方案下,P 同学与其舅舅(或舅母)单人相遇次数的期望为 3.25 次,方差为 0.04,相遇次数分布的离散程度极小。
5.2 方法优点
(1)Floyd 完备化思想:通过 Floyd 算法求出任意两节点间的最短路径,将其作为新边权重将非完备地铁网络转化为满足三角不等式的完备图,使最佳哈密尔顿圈与最佳推销员路径等价,从而将复杂问题纳入已知算法框架求解。
(2)2-opt 迭代优化:算法原理清晰、实现简洁,适用于中大规模节点(27个)的实时求解,迭代过程有保障收敛,不存在退化风险。
(3)最小生成树区域划分:利用 Prim 算法生成的最小生成树结构清晰、划分依据明确,为多旅行商路线问题的区域分解提供了具有结构性强的分解依据,使问题可分而治之。
5.3 模型局限与改进方向
(1)边权假设的简化:各站点间地铁运行时间采用往返均值处理,与实际略有偏差。若引入实时运行数据而非静态均值,建模精度可进一步提高。
(2)区域划分依赖人工判断:最小生成树划分5个区域时,依据的三个原则(分解点位置、连通性、环形逼近)依赖人工经验,缺乏严格的数学最优划分证明,未来可探索建立精确的区域划分优化模型。
(3)元启发式算法扩展:2-opt 属于局部搜索算法,对于更大规模网络可探索粒子群优化(PSO)、**遗传算法(GA)**等元启发式方法,在可接受的时间内获得近似最优解。