
第0章:技术栈与 Python 库说明
0.1 技术栈概览
本项目整体属于“离线特征工程 + 机器学习建模 + 业务策略落地”的典型风控建模方案,核心技术栈主要分为三层:
-
数据处理层 使用 Spark / PySpark 完成大规模样本加工、特征拼接、时间窗口聚合与批量导出,支撑海量特征在分布式环境下完成计算。
-
分析建模层 使用 Python 作为主要建模语言,结合 pandas、numpy、scikit-learn、lightgbm、toad 等库完成样本处理、特征筛选、模型训练、参数调优与效果评估。
-
业务应用层 将模型输出结果转化为可落地的催收筛选策略,包括主模型首轮检出、辅模型动态回捞,以及最终基于 ROI 的资源投放策略。
0.2 本项目依赖的主要技术
从全文代码实现来看,项目主要依赖以下技术组件:
- Python:核心开发语言
- Spark / PySpark:离线特征工程与分布式数据处理
- LightGBM:主模型训练与特征重要性排序
- scikit-learn:数据集划分、网格搜索与模型评估
- toad:特征筛选、IV 计算、风控建模辅助分析
- pandas / numpy:结构化数据处理与数值计算
第一章:项目背景与业务问题
1.1 长账龄订单的定义与行业痛点
在信贷业务中,贷后管理是风险控制闭环的最后一环。当一笔订单进入逾期阶段,催收力度的分配直接决定了人力成本的投入产出比。
所谓"长账龄订单",在本项目中定义为逾期 15 天及以上仍未还款的用户群体。这部分用户具有以下共同特点:
- 还款意愿低:经过 15 天以上的持续催收压力后仍拒绝还款,主观还款意愿已明显下降;
- 催收难度高:常规短信、电话催收对其触动有限,催收员需要投入更多精力;
- 正样本极度稀疏:经历 15 天以上催收后最终能成功还款的用户只占少数,数据分布严重倾斜。
1.2 现有通催模式的三大问题
在引入机器学习建模之前,业务侧对长账龄订单采用的是全量通催模式——即对所有长账龄订单统一安排人力进行催收。这种方式存在三个核心问题:
问题一:人力成本巨大
长账龄订单量大且持续累积,如果对每笔订单都投入人工催收,人力成本会线性增长。催收团队需要不断扩编,但回收金额的增长却远跟不上人力投入的增长。
问题二:ROI 极低
通催模式的整体人力 ROI(催回金额 / 人力成本)长期在 1.1 至 1.5 之间徘徊,催回效率仅为 5%。这个数字在扣除资金成本、运营成本后,几乎没有利润空间,甚至亏损。
问题三:影响团队士气
催收员每天拨打大量电话,接触的大多数是拒绝还款甚至态度恶劣的用户,成功率极低。长期如此,团队容易产生疲惫感,离职率上升,整体催收效率进一步下降,形成恶性循环。
1.3 项目目标:从"全量通催"到"精准检出 + 动态回捞"
基于上述痛点,核心问题是:
能否从大量长账龄订单中,自动化识别出具有高催回可能性的订单,并在阶段推进过程中持续回捞重新具备催回价值的订单,让有限的人力专注于最高价值的案件?
具体业务目标为:
| 指标 | 通催现状 | 目标值 |
|---|---|---|
| 人力 ROI | 1.1 ~ 1.5 | > 2.0 |
| 催回效率 | 5% | >10% |
| 催收策略 | 全量通催 | 主模型精准检出 + 辅模型动态回捞 |
项目整体思路如下:
- 特征构建:整合用户登录、APP 行为、设备信息、短信内容、基本信息等多维度数据,基于订单类型 × 行为标签 × 时间维度 × 指标值 × 计算方式五维交叉组合构建海量特征库(约万维);
- 多轮特征筛选:IV 值初筛(empty=0.6, iv=0.05, corr=0.8)→ LGBM 增益值稳定性复筛(5次随机建模×Top100交集)→ LGBM Top60 收敛,最终保留约 60 个高价值特征;
- LGBM 预测模型搭建:以"用户阶段内是否有还款"为标签(还款=1,未还款=0),训练主模型,对长账龄订单做首轮排序与检出;
- 辅模型动态回捞:围绕阶段内新增行为信号,对主模型未检出的订单进行二次识别,重点捕捉登录、他单还款、部分还款等重新转强的订单;
- ROI 导向落地:形成“主模型首轮检出 + 辅模型动态补充”的组合策略,在压缩人力投入的同时,持续提升检出质量与回收产出。
第二章:数据源与特征工程体系
2.1 数据源全景
本项目的数据来源覆盖了用户申请行为、信用表现、贷后催收交互以及 APP 内全链路行为四个维度,所有涉及用户隐私的数据均通过谷歌商店渠道合法授权获取,用户同意后方可采集。
(1)用户信息
用户在申请订单时授权抓取的数据,包含三个子模块:
- APP 列表:用户手机上安装的应用清单,通过谷歌商店渠道获取,能够侧面反映用户的生活消费习惯、金融需求密度等;
- 设备信息:申请订单时的设备参数,包括设备型号、品牌、操作系统版本等,用于判断用户设备的稳定性及是否存在多设备切换等风险行为;
- 短信信息:用户授权后结构化提取的短信内容,主要覆盖银行还款提醒短信、外部贷款平台短信等,能够反映用户的负债压力与资金紧张程度;
- 个人基本信息:用户在申请流程中主动填写的身份信息,包括年龄、职业、学历等人口统计学字段。
(2)风险维度
用户在申请订单时由外部数据源提供的信用指标,包括:
- 多头申请风险情况:该用户在多个信贷平台的申请记录情况,反映过度负债风险;
- 信用评级:外部征信或数据合作方给出的综合信用评分等级,直接反映用户的历史信用表现。
(3)催收信息
用户在进入长账龄阶段之前的贷后催记数据,包括入催前的历史催收记录、催收方式(短信/电话/外访)、历史催收结果等。催记信息能够帮助模型学习:在进入长账龄之前,哪些催收行为模式与最终的还款结果存在相关性。
(4)用户行为信息
用户在 APP 界面内的全链路操作日志,是本项目最细粒度的行为数据来源:
- 注册行为:注册时间、注册渠道、注册设备等;
- 登录行为:登录时间、登录频率、登录设备变更情况、登录地区变更等;
- 按键点击:各功能页面的点击热区分布、页面停留时长、页面跳转路径、申请流程中断节点等;
- APP 行为数据能够捕捉用户在产品内的主动参与程度,深层行为(如主动查看还款计划)往往与还款意愿高度相关。
2.2 特征维度的工程化构建
单一行为字段如果不经过时间窗口的交叉组合,直接入模效果往往很差。举个例子:“近 7 天登录次数"比"历史总登录次数"在长账龄场景的区分能力要强得多,因为近期行为更能反映用户当前的还款意愿。
本项目的特征构建采用了订单类型 × 行为标签 × 时间维度 × 指标值 × 计算方式五维交叉组合的工程化方案。以多头申请类特征为例,完整说明特征命名规范和构建逻辑。
2.2.1 特征命名规范
userMulti{订单类型}{行为标签}{指标值}{计算方式}{时间窗口}D
特征名直接携带业务含义,无需额外文档即可理解口径:
| 特征名 | 含义 |
|---|---|
userMultiAllAllOrderCnt7D |
近 7 天内,所有订单的申请次数 |
userMultiIsLoanAllAmountSum30D |
近 30 天内,已放款订单的总金额 |
userMultiIsNoLoanPackageDistinctCnt14D |
近 14 天内,未放款订单涉及的不同产品数 |
2.2.2 特征构建的三个维度
维度一:时间维度
按申请时间距离样本点的天数划分:1D、3D、7D、14D、30D、60D、All。
维度二:订单类型
按用户历史订单状态筛选子样本:
| 订单类型 | 含义 |
|---|---|
All |
全量历史订单 |
IsLoan |
历史上曾成功放款的订单 |
IsNoLoan |
历史上申请但未放款的订单 |
维度三:行为标签
在订单类型基础上进一步精细化筛选:
| 行为标签 | 含义 |
|---|---|
All |
不做额外筛选 |
Overdue1Day |
逾期≥1天的订单 |
Overdue3Day |
逾期≥3天的订单 |
PreRepay3Day |
提前≥3天还款的订单 |
2.2.3 指标值与计算方式
指标值(cal_field):覆盖历史订单全生命周期的关键字段:
| 指标值 | 含义 |
|---|---|
Package |
申请的产品 |
Order |
订单 ID |
Amount |
贷款金额 |
ApplyLendingInterval / ApplyRepaidInterval |
各节点时间间隔 |
OverdueDay / PreRepayDay |
逾期天数 / 提前还款天数 |
PartRepayAmt / PartRepayAmtPct |
部分还款金额及比例 |
计算方式:共 12 种,复用于所有指标值:
| 计算方式 | 含义 |
|---|---|
Cnt |
次数/笔数 |
DistinctCnt |
不同值数量 |
RepeatCnt |
重复次数(= Cnt - DistinctCnt) |
Sum |
求和 |
Avg |
均值 |
Max |
最大值 |
Min |
最小值 |
Std |
总体标准差 |
Skew |
偏度 |
Median |
中位数 |
Pct |
指定条件 / 全量条件的比例 |
DistinctPct |
不同值占比 |
特征生成公式:
特征 = 订单类型 + 行为标签 + 指标值 + 计算方式 + 时间窗口
示例解读:userMultiAllAllOrderCnt7D
- 订单类型 All(全量订单)
- 行为标签 All(无额外筛选)
- 指标值 Order(订单)
- 计算方式 Cnt(计数)
- 时间窗口 7D(近 7 天)
2.2.4 组合规模估算
订单类型(N) × 行为标签(M) × 时间窗口(T) × 指标值(K) × 计算方式(A)
= N × M × T × K × A 个特征
以多头申请类特征为例,假设有 3 种订单类型、10 种行为标签、7 个时间窗口、10 个指标值、12 种计算方式,单一多头申请模块即可生成 3 × 10 × 7 × 10 × 12 = 25200 个特征维度。
同样的逻辑应用于用户信息、风险维度、催收信息、用户行为信息等所有数据源,合计最终构建出海量的特征库
2.3 缺失值与异常值处理策略
海量特征中,原始数据中的空值来源复杂——可能是用户未授权、采集失败,也可能是业务上的无记录状态。本项目采用多级编码 + 排除式聚合的策略,而非简单的填充法。
2.3.1 多级空值编码体系
为每个原始字段额外生成一个 {指标值}_none 标记列,通过 get_is_none 函数将以下情况统一识别为空值标记:
def get_is_none(x):
if x is None or str(x).replace(' ','').lower().strip() in ['-999999','-999976','-999977','-999978',
'-999999.0','-999999.0000', '-999976.0','-999976.0000',
'-999977.0','-999977.0000', '-999978.0','-999978.0000',
'none','nan','nat','','000000000000000']:
return 1
else:
return 0
u_get_is_none = udf(get_is_none, IntegerType())
同时,对不同的异常情况赋予不同的编码值,模型训练时能够区分不同业务含义:
| 编码 | 含义 |
|---|---|
-999976 |
计算异常(类型转换失败等系统错误) |
-999977 |
被除数为空或除数为空 |
-999978 |
除数为 0 |
-999999 |
业务层面的空值(如用户未实际发生行为) |
2.3.2 排除式聚合
在生成聚合特征时,每个聚合计算的条件中强制过滤 {指标值}_none == 1 的记录:
if condition_label == 'All':
cal_condition = (f.col(time_field) <= time_windows_value) & (f.col(time_field) >= 0) & (f.col(f'{cal_field}_none') == 0 )
else:
cal_condition = (f.col(time_field) <= time_windows_value) & (f.col(time_field) >= 0) & (f.col(f'{cal_field}_none') == 0 ) & (f.col(f'type_{condition_label}') == 1)
这意味着:所有聚合特征(Cnt / Sum / Avg / Max 等)均基于有效记录计算,而非用统一填充值强行塞入模型。
2.3.3 工程实现逻辑
实际流程为两步:
第一步:对每个原始指标值字段,生成对应的 _none 标记列:
for cal_field in cal_field_list:
relative_df = relative_df.withColumn(f'{cal_field}_none', u_get_is_none(cal_field))
第二步:在聚合计算时,对每个聚合指标的聚合条件中加入 _none == 0 限制,确保空值记录不参与任何数学运算,从源头保证特征的质量。
2.4 技术实现:基于 Spark 的特征工程流水线
本节介绍如何基于 Spark 从数据库抽取原始数据,并经过 UDF 加工、多维聚合最终生成特征的全流程。代码均取自真实工程 ipynb 实现。
2.4.1 核心 UDF 定义
以下为 ipynb 中的核心自定义函数,用于时间处理、空值判断和关键业务指标计算:
(1)空值判断与除法安全
def get_is_none(x):
if x is None or str(x).replace(' ','').lower().strip() in ['-999999','-999976','-999977','-999978',
'-999999.0','-999999.0000', '-999976.0','-999976.0000',
'-999977.0','-999977.0000', '-999978.0','-999978.0000',
'none','nan','nat','','000000000000000']:
return 1
else:
return 0
u_get_is_none = udf(get_is_none, IntegerType())
def get_cal_division(numerator, denominator):
try:
if denominator == 0:
return -999978
elif get_is_none(numerator) or get_is_none(denominator):
return -999977
else:
return round(numerator / denominator, 2)
except Exception as e:
return -999976
(2)时区转换
def remove_tz(date_time):
return datetime.strptime(date_time.strftime('%Y-%m-%d %H:%M:%S'), '%Y-%m-%d %H:%M:%S')
def convert_to_nigeria_time(date_time):
if type(date_time) == str:
date_time_d = str(date_time)[0:19]
else:
date_time_d = date_time.strftime('%Y-%m-%d %H:%M:%S')
time_stamp = time.mktime(time.strptime(date_time_d, '%Y-%m-%d %H:%M:%S'))
utc_dt = datetime.utcfromtimestamp(time_stamp).replace(tzinfo=pytz.utc)
dest_tz = timezone('Africa/Lagos')
dest_dt = dest_tz.normalize(utc_dt.astimezone(dest_tz))
return remove_tz(dest_dt)
def change_to_nigeria(date_time):
if get_is_none(date_time):
return None
else:
return convert_to_nigeria_time(date_time)
u_change_to_nigeria = udf(change_to_nigeria, TimestampType())
(3)时间间隔计算
def get_timedelta_strtime(time_end, time_start):
try:
if get_is_none(time_end) or get_is_none(time_start):
return None
if len(str(time_end)) < 15 and len(str(time_start)) < 15:
time_start = datetime.strptime(str(time_start)[0:10], "%Y-%m-%d")
time_end = datetime.strptime(str(time_end)[0:10], "%Y-%m-%d")
elif len(str(time_end)) < 15 and len(str(time_start)) > 15:
time_start = datetime.strptime(str(time_start)[0:19], "%Y-%m-%d %H:%M:%S")
time_end = datetime.strptime(str(time_end)[0:10], "%Y-%m-%d")
else:
time_start = datetime.strptime(str(time_start)[0:19], "%Y-%m-%d %H:%M:%S")
time_end = datetime.strptime(str(time_end)[0:19], "%Y-%m-%d %H:%M:%S")
seconds = (time_end - time_start).total_seconds()
if seconds < 0:
seconds = None
return seconds
except Exception as e:
return -999976
u_get_timedelta_strtime = udf(get_timedelta_strtime, FloatType())
(4)提前还款天数计算
def get_pre_repay_day(real_repay_time, due_time, is_repay):
if str(is_repay) in ['1', '1.0']:
if get_is_none(real_repay_time):
return -999999
elif get_is_none(due_time):
return -999999
else:
real_repay_time = datetime.strptime(str(real_repay_time)[0:10], "%Y-%m-%d")
due_time = datetime.strptime(str(due_time)[0:10], "%Y-%m-%d")
pre_repayday = int((due_time - real_repay_time).days)
if pre_repayday < 0:
pre_repayday = -999999
return pre_repayday
else:
return -999999
u_get_pre_repay_day = udf(get_pre_repay_day, IntegerType())
2.4.2 核心聚合函数:get_agg_v2
该函数封装了 12 种聚合计算逻辑,输入五维参数后自动构建 Spark 聚合表达式,是整个特征工程流水线的核心:
def get_agg_v2(time_field, dt_, condition_label, condition_type, cal_field, cal_type, fea_name):
"""
聚合函数
:param time_field:
:param dt_:
:param contact_condition:
:param cal_field:
:param cal_type:
:return:
"""
print(f"export feature:{fea_name}")
if dt_ != 'All':
time_windows_value = dt_ * 24 * 60 * 60
else:
time_windows_value = 1000 * 24 * 60 * 60
if condition_label == 'All':
cal_condition = (f.col(time_field) <= time_windows_value) & (f.col(time_field) >= 0) & (f.col(f'{cal_field}_none') == 0)
else:
cal_condition = (f.col(time_field) <= time_windows_value) & (f.col(time_field) >= 0) & (f.col(f'{cal_field}_none') == 0) & (f.col(f'type_{condition_label}') == 1)
if condition_type != 'All':
cal_condition = cal_condition & (f.col(f'type_{condition_type}') == 1)
if cal_type == 'Std':
return f.stddev_pop(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'Avg':
return f.mean(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'Sum':
return f.sum(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'sumDistinct':
return f.sumDistinct(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'Max':
return f.max(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'Skew':
return f.skewness(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'Median':
return f.percentile_approx(f.when(cal_condition, f.col(cal_field)), 0.5).alias(fea_name)
elif cal_type == 'Min':
return f.min(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'Cnt':
return f.count(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'DistinctCnt':
return f.countDistinct(f.when(cal_condition, f.col(cal_field))).alias(fea_name)
elif cal_type == 'RepeatCnt':
return (f.count(f.when(cal_condition, f.col(cal_field))) - f.countDistinct(f.when(cal_condition, f.col(cal_field)))).alias(fea_name)
elif cal_type == 'DistinctPct':
all_condition = (f.col(time_field) <= time_windows_value) & (f.col(time_field) >= 0) & (f.col(f'{cal_field}_none') == 0)
return (f.countDistinct(f.when(cal_condition, f.col(cal_field))) / f.countDistinct(f.when(all_condition, f.col(cal_field)))).alias(fea_name)
elif cal_type == 'Pct':
all_condition = (f.col(time_field) <= time_windows_value) & (f.col(time_field) >= 0) & (f.col(f'{cal_field}_none') == 0)
return (f.count(f.when(cal_condition, f.col(cal_field))) / f.count(f.when(all_condition, f.col(cal_field)))).alias(fea_name)
elif cal_type == 'RepeatPct':
all_condition = (f.col(time_field) <= time_windows_value) & (f.col(time_field) >= 0) & (f.col(f'{cal_field}_none') == 0)
return ((f.count(f.when(cal_condition, f.col(cal_field))) - f.countDistinct(f.when(cal_condition, f.col(cal_field))))
/ (f.count(f.when(all_condition, f.col(cal_field))) - f.countDistinct(f.when(all_condition, f.col(cal_field))))).alias(fea_name)
return None
2.4.3 数据预处理 + 聚合特征生成
整个流水线的核心封装类,包含数据预处理(prepare_df)和批量聚合(feature_df)两个方法:
class Features1(object):
def __init__(self, spark: SparkSession):
self.spark = spark
def prepare_df(self, from_sample, prepare_table):
# 加载订单表
self.spark.sql(f""" select * from
risk.dw_order_info_slice_2
where
country = 'NIGERIA'
and merchant_id = 1
and not isnull(APPLY_DAY)
""") \
.createOrReplaceTempView('loan_df')
col_list = self.spark.sql("select * from risk.dw_order_info_slice_2").columns
col_list.remove('REPAY_TIME_FORMAT')
col_list = [f"o.{x} as SAMPLE_{x}" for x in col_list]
# 关联样本表与订单表
self.spark.sql(f"""
select {','.join(col_list)}, s.due_day as SAMPLE_REPAY_TIME_FORMAT,
to_date(s.d14_date) as SAMPLE_d14_date,
date_add(to_date(s.d14_date), 1) as SAMPLE_APPLY_LIMIT_DAY
from
{from_sample} s left join risk.dw_order_info_slice_2 o
on s.bis_order_id = o.bis_order_id
where
country = 'NIGERIA' and merchant_id = 1
""").createOrReplaceTempView('sample_order')
self.spark.sql("""
select s.* , l.* from
sample_order s left join loan_df l
on s.SAMPLE_BIS_USER_ID = l.BIS_USER_ID
where
l.APPLY_DAY < S.SAMPLE_APPLY_LIMIT_DAY
and S.SAMPLE_APPLY_TIME < l.APPLY_TIME
and s.SAMPLE_BIS_ORDER_ID != l.BIS_ORDER_ID
""").createOrReplaceTempView('sample_df')
relative_df = self.spark.sql("select * from sample_df")
# 时区转换
relative_df = relative_df.withColumn('LENDING_TIME_FORMAT', u_get_time_process('LENDING_TIME_FORMAT', 'SAMPLE_APPLY_LIMIT_DAY'))
relative_df = relative_df.withColumn('REPAIED_TIME_FORMAT', u_get_time_process('REPAIED_TIME_FORMAT', 'SAMPLE_APPLY_LIMIT_DAY'))
relative_df = relative_df.withColumn('SAMPLE_APPLY_TIME_NI', u_change_to_nigeria('SAMPLE_APPLY_TIME'))
relative_df = relative_df.withColumn('LENDING_TIME_TIMESTAMP_NI', u_change_to_nigeria('LENDING_TIME_FORMAT'))
relative_df = relative_df.withColumn('REPAIED_TIME_TIMESTAMP_NI', u_change_to_nigeria('REPAIED_TIME_FORMAT'))
relative_df = relative_df.withColumn('APPLY_TIME_NI', u_change_to_nigeria('APPLY_TIME'))
relative_df = relative_df.withColumn('SAMPLE_APPLY_DAY_NI', u_get_date_from_timestamp('SAMPLE_APPLY_TIME_NI'))
# 生成时间间隔字段(秒)
relative_df = relative_df.withColumn('ApplyLendingInterval', u_get_timedelta_strtime('LENDING_TIME_TIMESTAMP_NI', 'SAMPLE_APPLY_TIME_NI'))
relative_df = relative_df.withColumn('ApplyApplyInterval', u_get_timedelta_strtime('APPLY_TIME_NI', 'SAMPLE_APPLY_TIME_NI'))
relative_df = relative_df.withColumn('ApplyRepaiedInterval', u_get_timedelta_strtime('REPAIED_TIME_TIMESTAMP_NI', 'SAMPLE_APPLY_TIME_NI'))
relative_df = relative_df.withColumn('LimitApplyInterval', u_get_timedelta_strtime('SAMPLE_APPLY_LIMIT_DAY', 'APPLY_TIME'))
# 生成业务标签字段
relative_df = relative_df.withColumn('is_reject', u_get_value_equals(30)(col('STATUS')))
relative_df = relative_df.withColumn('is_cancel', u_get_value_equals(60)(col('STATUS')))
relative_df = relative_df.withColumn('is_loan', u_get_is_loan('LENDING_TIME_TIMESTAMP_NI', 'SAMPLE_APPLY_LIMIT_DAY'))
relative_df = relative_df.withColumn('is_repay', u_get_is_repay('REPAIED_TIME_TIMESTAMP_NI'))
# 生成日期字段
relative_df = relative_df.withColumn('ApplyDays', u_get_message_day('APPLY_TIME_NI'))
relative_df = relative_df.withColumn('LendingDays', u_get_message_day('LENDING_TIME_TIMESTAMP_NI'))
relative_df = relative_df.withColumn('RepayDays', u_get_message_day('REPAIED_TIME_TIMESTAMP_NI'))
relative_df = relative_df.withColumn('repay_date', u_get_message_day('REPAIED_TIME_TIMESTAMP_NI'))
relative_df = relative_df.withColumn('due_date', u_get_message_day('ORG_REPAY_TIME'))
relative_df = relative_df.withColumn('PreRepayDay', u_get_pre_repay_day('repay_date', 'due_date', 'is_repay'))
# 生成实还金额、部分还款相关字段
relative_df = relative_df.withColumn('REPAIED_AMOUNT_FIX', u_get_repaid_amount('REPAY_AMOUNT', 'REPAIED_AMOUNT', 'is_repay'))
relative_df = relative_df.withColumn('REPAIED_AMOUNT_FIX', get_none_defalut_value(0)(col('REPAIED_AMOUNT_FIX')))
relative_df = relative_df.withColumn('REPAY_AMOUNT', get_none_defalut_value(0)(col('REPAY_AMOUNT')))
relative_df = relative_df.withColumn('IsPartRepay', u_is_part_repay('is_repay', 'REPAIED_AMOUNT_FIX', 'REPAY_AMOUNT'))
relative_df = relative_df.withColumn('PartRepayAmtPct', u_get_part_repay_amount_pct('is_repay', 'REPAIED_AMOUNT_FIX', 'REPAY_AMOUNT'))
relative_df = relative_df.withColumn('PartRepayAmt', u_get_part_repay_amount('IsPartRepay', 'REPAIED_AMOUNT_FIX', 'REPAY_AMOUNT'))
# 生成布尔标签字段
relative_df = relative_df.withColumn('IsRepay', u_get_value_equals(1)(col('is_repay')))
relative_df = relative_df.withColumn('IsLoan', u_get_value_equals(1)(col('is_loan')))
relative_df = relative_df.withColumn('IsNoLoan', u_get_value_equals(0)(col('is_loan')))
relative_df = relative_df.withColumn('IsCancel', u_get_value_equals(1)(col('is_cancel')))
relative_df = relative_df.withColumn('IsReject', u_get_value_equals(1)(col('is_reject')))
relative_df = relative_df.withColumn('IsOnLoan', u_is_on_loan('is_loan', 'is_repay'))
relative_df = relative_df.withColumn('IsOnTimeRepay', u_is_on_time_repay('is_repay', 'PreRepayDay'))
# 字段重命名
relative_df = relative_df.withColumnRenamed('LENDING_AMOUNT', 'Amount')
relative_df = relative_df.withColumnRenamed('BIS_ORDER_ID', 'Order')
relative_df = relative_df.withColumnRenamed('PACKAGE_ID', 'Package')
# 生成行为标签 type_* 字段
for t in con_list_all:
if t == 'All':
relative_df = relative_df.withColumn(f'type_{t}', u_get_all('Order'))
elif t == 'PreRepay1Day':
relative_df = relative_df.withColumn(f'type_{t}', u_get_value_ge(1)(col('PreRepayDay')))
elif t == 'PreRepay0Day':
relative_df = relative_df.withColumn(f'type_{t}', u_get_value_equals(0)(col('PreRepayDay')))
elif t == 'IsPartRepayAmt7Pct':
relative_df = relative_df.withColumn(f'type_{t}', u_get_value_between(0, 0.7)(col('PreRepayDay')))
else:
relative_df = relative_df.withColumn(f'type_{t}', u_get_value_equals(1)(col(t)))
# 为每个原始字段生成 _none 标记列
for cal_field in cal_field_list:
relative_df = relative_df.withColumn(f'{cal_field}_none', u_get_is_none(cal_field))
# 写出预处理结果
relative_df.coalesce(64).write.mode('overwrite').saveAsTable(prepare_table)
def generate_agg_list(self):
agg_list = list()
for con in cal_fea_dict.keys():
condition_list = cal_fea_dict[con]['con']
cal_list = cal_fea_dict[con]['cal_field']
for con_key in condition_list:
for dt in dt_list:
cal_dict = {}
for cal_field in cal_list:
cal_dict[cal_field] = cal_dict_all[cal_field]
for cal_type in cal_dict[cal_field]:
fea_name = f'userALS3Multi{con}{con_key}{cal_field}{cal_type}{str(dt)}D'
agg_list.append(get_agg_v2(
time_field='LimitApplyInterval', dt_=dt,
condition_label=con, condition_type=con_key,
cal_field=cal_field, cal_type=cal_type,
fea_name=fea_name
))
return agg_list
def feature_df(self, df: DataFrame, repartition_num, coalesce_num, table_name, mode):
groupby_field_list = ['BIS_ORDER_ID']
agg_list = self.generate_agg_list()
index = 1
# 分10批写入 CSV,避免内存溢出
for l in np.array_split(agg_list, 10):
df.groupby([f'SAMPLE_{x}' for x in groupby_field_list]).agg(*l) \
.coalesce(coalesce_num).write.mode(mode).option("header", "true").csv(f"{table_name}_{index}.csv")
index += 1
2.4.4 流水线执行
# 初始化并执行预处理
fea = Features1(spark)
fea.prepare_df(from_sample='risk_analysis.sample_df_S3_20230727', prepare_table='risk_analysis.multiALS3_prepare_20230727')
# 加载预处理结果并执行特征聚合
df = spark.sql("select * from risk_analysis.multiALS3_prepare_20230727")
fea.feature_df(df, repartition_num=0, coalesce_num=64, table_name='multiALS3_features_20230727', mode='overwrite')
2.4.5 合并导出特征 CSV
import pandas as pd
multi_features_S3 = []
for i in range(10):
print(i)
result = spark.read.csv(f"multiALS3_features_20230727_{i+1}.csv")
result_df = result.toPandas()
result_df.columns = result_df.values.tolist()[0]
result_df = result_df[result_df['SAMPLE_BIS_ORDER_ID'] != 'SAMPLE_BIS_ORDER_ID']
result_df = result_df.reset_index(drop=True)
if len(multi_features_S3) == 0:
multi_features_S3 = result_df
else:
multi_features_S3 = multi_features_S3.merge(result_df, on='SAMPLE_BIS_ORDER_ID', how='outer')
print(multi_features_S3.shape)
multi_features_S3.to_csv('../multiALS3_features_20230727.csv')
整个流水线覆盖数据关联 → 时区转换 → 时间间隔计算 → 业务标签生成 → 空值标记 → 多维聚合 → 分批写出 → 合并导出全链路,基于 Spark 分布式计算,能够支撑海量特征在小时级别内完成构建。
第三章:样本选取
3.1 Y 标签定义
模型的目标是预测长账龄订单在后续一段时间内是否会发生还款。
标签初始方案:以"是否结清"作为标签——结清=1,未结清=0。然而在实际数据分析后发现,长账龄订单中结清比例极低(不足 5%),数据偏度极大,正负样本严重失衡,模型难以有效学习。
最终方案:改为以"阶段内是否有还款"作为标签——阶段内有还款=1,阶段内未还款=0。通过这一口径调整,正样本占比从不足 5% 提升至 6.5%,数据偏度明显改善,模型学习效果大幅提升。
# 标签生成逻辑
sample['target'] = sample['d21Amount'] # d21Amount > 0 → 有还款 → target=1
sample['flag'] = sample['create_date'].astype('str').apply(lambda x: x >= '2023-07-28')
sample = sample.rename(columns={'bis_order_id': 'BIS_ORDER_ID'})
3.2 正负样本量
全量样本共 22,895 条,正负样本分布如下:
| 标签 | 含义 | 样本数 | 占比 |
|---|---|---|---|
| 1 | 阶段内有还款 | ~21,413 | ~93.5% |
| 0 | 阶段内未还款 | ~1,482 | ~6.5% |
正样本(还款)占绝大多数,负样本(未还款)约占 6.5%,属于典型的高度不平衡二分类问题,这也是后续建模中需要通过特征筛选和模型调参重点关注的难点。
3.3 训练 / 验证 / 测试集划分
采用随机划分方式,以日期作为辅助切分标志,将样本划分为三个独立集合:
# 以 2023-07-28 为节点,之前的样本用于训练和测试,该日期之后的样本用于验证
sample['flag'] = sample['create_date'].astype('str').apply(lambda x: x >= '2023-07-28')
# flag=0 的样本随机划分 70% 训练集、30% 测试集
train, test = train_test_split(
sample[sample['flag'] == 0],
test_size=0.3,
random_state=23123
)
# flag=1 的样本全部作为验证集
vld = sample[sample['flag'] == 1]
划分结果:
| 数据集 | 样本数 | 正样本占比 | 负样本占比 |
|---|---|---|---|
| train | 14,377 | 93.50% | 6.50% |
| test | 6,162 | 93.36% | 6.64% |
| vld(验证集) | 2,356 | 93.93% | 6.07% |
三个数据集的正负样本分布高度一致,说明随机划分在统计上是稳定的,各集合之间的分布差异在 0.5% 以内,不存在数据泄漏风险,验证集能够客观反映模型的泛化能力。
第四章:特征筛选
4.0 前置知识介绍
在正式进入特征筛选方法之前,先补充两个核心概念:IV 值和 LGBM 的 gain 指标。前者用于衡量单个特征的区分能力,后者用于衡量特征在树模型中的实际贡献度,两者共同构成了本项目特征筛选的理论基础。
4.0.1 IV 值的原理
IV(Information Value)值是信用评分领域最经典的特征筛选指标,用于衡量单个特征对目标变量的区分能力,其计算逻辑基于 WoE(Weight of Evidence)。
WoE 的直观理解:对于二分类问题(还款=1 / 未还款=0),WoE 反映的是该特征取某个值时,未还款样本与还款样本的比例差异。
- WoE > 0:该区间内未还款的比例高于还款的比例,该特征取值与负样本(未还款)正相关;
- WoE < 0:该区间内未还款的比例低于还款的比例,该特征取值与正样本(还款)正相关;
- |WoE| 越大,该区间的区分能力越强。
IV 的计算:IV 是各区间 WoE 值的加权求和,权重为(未还款占比 - 还款占比)。每个区间对 IV 的贡献越大,说明该区间对目标变量的区分能力越强。IV 值越大,说明该特征对还款与未还款的区分能力越强。
业界 IV 判读标准:
| IV 值范围 | 特征效果判断 |
|---|---|
| < 0.02 | 无用特征,不具备区分能力 |
| 0.02 ~ 0.1 | 弱特征,区分能力有限 |
| 0.1 ~ 0.3 | 中等特征,具有一定区分能力 |
| 0.3 ~ 0.5 | 强特征,区分能力强 |
| > 0.5 | 过于强(需人工排查是否存在数据泄漏) |
本项目 IV 筛选阈值为 0.05,即 IV < 0.05 的特征直接剔除。
4.0.2 LGBM 模型的 Gain 指标
除了 IV 这类单变量指标外,本项目在第二轮特征筛选中还引入了 LightGBM 的 gain 指标,用于衡量特征在树模型中的实际贡献度。
Gain 的直观理解:在 LightGBM 每一次节点分裂时,模型都会选择一个特征和切分点,使当前目标函数下降得最多。这个“下降量”就是该次分裂带来的增益(gain)。一个特征如果在多棵树、多次分裂中持续带来较大的目标函数下降,说明它对模型预测结果的贡献更高。
- Gain 越大:说明该特征在模型中的实际解释力和区分能力越强;
- Gain 越小:说明该特征虽然可能在单变量下有区分度,但放到多特征组合场景后贡献有限;
- 如果某个特征只在单次建模中 gain 很高,但在不同随机划分下波动很大,则说明其稳定性不足。
与 IV 不同,gain 是多变量场景下的模型内生指标。IV 更适合做第一轮粗筛,快速剔除明显无效的弱特征;gain 更适合做第二轮复筛,判断特征在真实建模过程中的稳定贡献。因此,本项目采用了“IV 初筛 + gain 复筛”的组合方式来完成特征收敛。
4.1 初筛:信息值(IV)筛选
海量特征经过空值处理后,仍存在大量区分能力不足或与其他特征高度相关的冗余特征。如果全部入模,不仅训练成本极高,还容易引入噪声、导致模型过拟合。因此,在正式建模之前,需要进行两轮特征筛选逐步收敛特征规模。
4.1.1 初筛实现
使用 toad 库的 selection.select 方法,以 IV 值和相关性为主要筛选依据,同时过滤高频空值特征:
import toad
for k in feature_dict.keys():
print(k)
f_df = pd.read_csv(feature_dict[k] + '.csv')
join_df = sample[sample['flag'] == 0][['target', 'BIS_ORDER_ID']] \
.merge(f_df.rename(columns={'SAMPLE_BIS_ORDER_ID': 'BIS_ORDER_ID'}),
on='BIS_ORDER_ID', how='inner')
col_list = list(join_df.columns[2:])
select_df = toad.selection.select(
join_df[col_list].fillna(-999999),
target=join_df['target'],
empty=0.6, # 空值率 > 60% 的特征剔除
iv=0.05, # IV < 0.05 的特征剔除
corr=0.8, # 相关系数 > 0.8 的特征对取其一
return_drop=False,
exclude=None
)
select_col = list(select_df.columns)
print(f'feature_shape:{f_df.shape}, train_join_shape:{len(select_col)}')
select_col_dict[k] = select_col
筛选参数解读:
| 参数 | 含义 |
|---|---|
empty=0.6 |
空值率超过 60% 的特征剔除 |
iv=0.05 |
IV 值低于 0.05 的特征剔除 |
corr=0.8 |
两两特征相关系数超过 0.8 时,保留 IV 更高的那个 |
4.2 复筛:增益值稳定性筛选
4.2.1 稳定性筛选原理
IV 筛选存在两个局限:一是 IV 值依赖分箱方式,不同分箱粒度可能产生不同的排序;二是 IV 是单变量指标,无法反映多特征组合后的实际增益。因此,需要通过 LightGBM 的实际建模来验证每个特征在多变量场景下的真实贡献度。
为了防止单次建模的偶然性,采用随机划分 + 多次建模 + 交集筛选的策略:5 次随机划分、每次取 Top 100 增益值特征,最终保留在至少 4 次(即 sum >= 4)中都进入 Top 100 的特征。
4.2.2 复筛实现
import lightgbm as lgb
import numpy as np
total_test_df = pd.concat([train_, test_], axis=0, ignore_index=True)
df_list = np.array_split(total_test_df, 5)
feature_name_dict = {}
for i in [0, 1, 2, 3, 4]:
print(f"i = {i}")
# 其余4份做训练,第i份做测试
d_train_list = [df_list[x] for x in [0, 1, 2, 3, 4] if x != i]
t_train = pd.concat(d_train_list, axis=0, ignore_index=True)
t_test = df_list[i]
col_list = [x for x in list(train_.columns)[2:] if ':' not in x]
X_train = t_train[col_list].fillna(-999999)
y_train = t_train['target']
X_test = t_test[col_list].fillna(-999999)
y_test = t_test['target']
X_vld = vld_[col_list].fillna(-999999)
y_vld = vld_['target']
# 开启样本不平衡处理
model_train2 = lgb.LGBMClassifier(is_unbalance=True)
choose_model = model_train2
choose_model.fit(X_train, y_train)
# 获取增益值并取 Top100
gain = choose_model.booster_.feature_importance('gain')
fi = pd.DataFrame({
'feature': list(X_train.columns),
'split': choose_model.booster_.feature_importance('split'),
'gain': 100 * gain / gain.sum()
}).sort_values('gain', ascending=False)
top_feature = fi.head(100)
feature_name_dict[i] = top_feature
# 打印各折训练/测试/验证集指标
print("train_auc:{}, test_auc:{}, vld_auc:{}".format(...))
print("train_ks:{}, test_ks:{}, vld_ks:{}".format(...))
4.2.3 交集筛选
# 5次建模的 Top100 特征取交集
feature_select_df = pd.DataFrame()
for i in [0, 1, 2, 3, 4]:
f_list = feature_name_dict[i]['feature'].to_list()
temp_df = pd.DataFrame({'f_name': f_list, f'{i}_select': 1})
if feature_select_df.empty:
feature_select_df = temp_df
else:
feature_select_df = feature_select_df.merge(temp_df, on='f_name', how='outer')
feature_select_df = feature_select_df.fillna(0)
# 统计每个特征在5次建模中进入 Top100 的次数
feature_select_df['sum'] = feature_select_df.apply(
lambda x: np.sum([x[f'{i}_select'] for i in [0, 1, 2, 3, 4]]), axis=1
)
# 至少4次进入 Top100 → 最终入选
select_col_list = feature_select_df[feature_select_df['sum'] >= 4]['f_name'].to_list()
训练过程截图

复筛特征集(节选)
4.2.4 最终筛选:标准 LGBM Top 60 增益值
经过两轮筛选后,还需进行最后一轮筛选,以标准 LightGBM 模型在全部训练集上做一次完整训练,选取增益值(gain)排名前 60 的特征作为最终入模版本。这一步的目的是确保最终入模的特征在完整数据集上具有最强的区分能力,同时也是对前两轮筛选结果的再一次验证与收敛。
# 最终一次标准 LGBM 训练,取增益值 Top60 作为最终特征集
model_train2 = lgb.LGBMClassifier(is_unbalance=True)
choose_model = model_train2
choose_model.fit(X_train, y_train)
gain = choose_model.booster_.feature_importance('gain')
fi = pd.DataFrame({
'feature': list(X_train.columns),
'split': choose_model.booster_.feature_importance('split'),
'gain': 100 * gain / gain.sum()
}).sort_values('gain', ascending=False).reset_index(drop=True)
# 取前60 → 最终入选特征
top_feature = fi.head(60)
最终确定的特征集(TOP20)
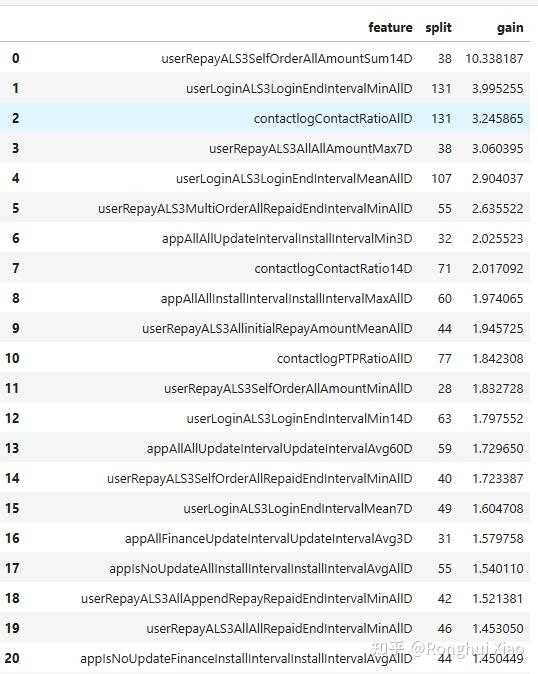
4.2.5 筛选结果汇总
经过四轮筛选,特征规模从万量级逐步收敛至约 60 个高价值特征,进入正式建模阶段:
| 阶段 | 特征数量 | 筛选方法 |
|---|---|---|
| 原始特征 | 万量级 | — |
| IV 初筛后 | 千量级别 | toad selection:empty=0.6, iv=0.05, corr=0.8 |
| 增益值稳定性复筛后 | ~82 | 5 次随机建模 × Top100 × 交集(sum ≥ 4) |
| 最终 Top60 筛选后 | ~60 | 标准 LGBM 增益值排序取前 60 |
这约 60 个特征经过四轮筛选(空值处理 → IV 初筛 → 稳定性复筛 → LGBM Top60),是从万量级特征池中层层收敛而来的高稳健性特征,具备强区分能力,是模型能够在长账龄场景下达到 AUC 69 的重要基础。
第五章:LightGBM 模型搭建与训练
5.0 LightGBM 模型介绍、重要参数与评估标准
5.0.1 LightGBM 选型背景
LightGBM(Light Gradient Boosting Machine)是一种基于梯度提升决策树(GBDT)的高效集成学习算法。相比传统 GBDT,LightGBM 采用了直方算法(Histogram) 和叶节点优先(Leaf-wise) 生长策略,大幅提升了训练速度,同时保持了良好的预测精度,在工业界风控模型中被广泛使用。
选择 LightGBM 的三个核心原因:
- 稀疏数据友好:对高维稀疏特征的处理效率高,适合本项目大量空值特征的场景;
- 可解释性:可输出特征增益值(gain)和分裂次数(split),便于分析特征重要性;
- 训练速度快:相比 XGBoost,LightGBM 在大数据量场景下训练速度有数量级提升。
5.0.2 重要参数说明
本模型训练中涉及的关键参数及作用如下:
| 参数 | 含义 | 本项目最优值 |
|---|---|---|
boosting_type |
提升方式,固定为 gbdt | 'gbdt' |
objective |
目标函数 | 'Binary' |
learning_rate |
学习率,控制每轮迭代的步长 | 0.01 |
n_estimators |
迭代轮数,总共构建的树数量 | 300 |
max_depth |
单棵树的最大深度,限制模型复杂度防过拟合 | 2 |
num_leaves |
叶子节点数,配合 max_depth 控制模型复杂度 | 3 |
min_child_samples |
叶子节点的最小样本数,避免少数样本主导分裂 | 20 |
min_child_weight |
叶子节点的最小权重 | 0.001 |
min_split_gain |
分裂最小增益阈值 | 0 |
reg_alpha |
L1 正则化系数,使部分特征权重收缩为 0 | 0.03 |
reg_lambda |
L2 正则化系数,使特征权重整体平滑 | 0.01 |
subsample |
行采样比例 | 1 |
subsample_for_bin |
构建直方图时的采样行数 | 200000 |
subsample_freq |
子采样频率 | 12 |
colsample_bytree |
列采样比例 | 1(调参搜索时为 0.99) |
is_unbalance |
开启样本不平衡处理 | True |
max_bin |
分箱数,特征值分箱的桶数 | 900 |
importance_type |
特征重要性类型 | 'split' |
silent |
是否静默训练 | True |
5.0.3 参数训练方法
本项目的超参数训练并不是一次性黑盒搜索完成,而是结合业务目标与过拟合控制要求,采用了枚举法 + 交叉验证 + GridSearchCV + 多指标排序的组合方式,逐步收敛到最终参数。
具体使用了以下几类方法:
- 枚举法(Manual Enumeration):对学习率、迭代轮数、正则化系数、最小样本数等参数按预设范围逐组遍历,优点是搜索路径清晰、便于结合业务经验控制范围;
- LightGBM 原生交叉验证
lgb.cv:在第一轮调参中,对不同learning_rate × n_estimators组合做 5 折交叉验证,以 CV AUC 均值比较不同组合的泛化效果; - GridSearchCV 网格搜索:在第二轮调参中,对
max_depth与num_leaves做标准网格搜索,自动遍历参数组合并返回最优的 5 折 CV AUC 结果; - 多指标人工排序:在第三轮调参中,不仅看单一 AUC,还同时计算训练集、测试集、验证集的 AUC / KS,以及
diff_ks、diff_auc、cur_std等稳定性指标,再按业务目标选择最优参数组合。
这种分步训练方式的核心思路是:先用交叉验证确定大方向参数,再用网格搜索收敛树结构,最后用多指标排序控制过拟合风险,从而兼顾模型效果、稳定性与可解释性。
5.0.4 模型训练流程
拿到 60 个最有特征
│
▼
┌──────────────────────────────┐
│ 第一步:学习率与轮数枚举 │
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ 第二步:max_depth 与 │
│ num_leaves 枚举 │
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ 第三步:L1/L2 正则化与 │
│ 最小样本数枚举 │
└──────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ 最优模型参数 │
└──────────────────────────────┘
5.0.5 模型评估标准
本模型采用四个核心评估指标:
AUC(Area Under ROC Curve)
ROC 曲线下面积,反映模型对正负样本的排序能力。定义为:
AUC = ∫₀¹ TPR(FPR⁻¹(x)) dx
等价计算方式:所有正负样本对中,模型对正样本的打分高于负样本的比例。
AUC = Σᵢ Σⱼ 1[Pᵢ > Pⱼ] / (n₊ × n₋)
(其中 n₊ 为正样本数,n₋ 为负样本数,1[·] 为指示函数)
业界标准:AUC > 65 为模型有效,AUC > 70 为良好。
KS(Kolmogorov-Smirnov)
衡量好坏样本在评分分布上的最大差距,定义为:
KS = maxₜ |TPR(t) − FPR(t)|
即 ROC 曲线上 TPR 与 FPR 之间最大垂直距离。KS 越高,区分度越强。
业界标准:KS > 30 为有效,KS > 40 为良好。
Precision(精确率)
模型预测为正样本的订单中,实际也属于该正样本类别的比例。其含义取决于建模时将哪一类设为正类:
Precision = TP / (TP + FP)
Recall(召回率)
实际正样本中被模型成功预测出来的比例:
Recall = TP / (TP + FN)
5.1 初版模型与过拟合问题
使用稳定性筛选后的 46 个特征搭建基准 LightGBM 模型,开启样本不平衡处理 is_unbalance=True,直接训练后的评估结果如下:
train_auc: 99.98 | test_auc: 64.54 | vld_auc: 59.00
train_ks: 99.20 | test_ks: 24.54 | vld_ks: 15.90
问题诊断:训练集 AUC 高达 99.98,几乎完美拟合,但测试集和验证集 AUC 仅在 60 左右,模型处于严重过拟合状态——训练集与验证集之间存在巨大的性能断层,说明模型在训练数据上学到了过多噪声,不具备泛化能力。
5.2 超参调优方法
针对过拟合问题,采用枚举法 + 交叉验证策略,分三步系统化调优所有关键参数。
5.2.1 第一步:学习率与轮数枚举
通过 5 折交叉验证,枚举 7 种学习率 × 3 种 n_estimators 的组合(共 21 组),以 CV AUC 均值最优为准则:
lr_dict = dict()
for rate in [0.01, 0.03, 0.06, 0.1, 0.3, 0.6, 1]:
for num_boost_round in [100, 300, 600]:
params = {
'boosting_type': 'gbdt',
'objective': 'Binary',
'learning_rate': rate,
'is_unbalance': True
}
data_train = lgb.Dataset(X_train_, y_train_, silent=True)
cv_results = lgb.cv(
params, data_train,
num_boost_round=num_boost_round,
early_stopping_rounds=int(num_boost_round / 2),
nfold=5, verbose_eval=False,
seed=3432141,
metrics='auc', show_stdv=False
)
lr_dict[f"{rate}_{num_boost_round}"] = (
cv_results['auc-mean'][-1],
len(cv_results['auc-mean'])
)
CV 结果汇总(按 AUC 均值排序):
| 学习率 | 轮数 | CV_AUC |
|---|---|---|
| 0.01 | 600 | 0.7170 |
| 0.01 | 300 | 0.7170 |
| 0.01 | 100 | 0.7170 |
| 0.03 | 600 | 0.7030 |
| 0.06 | 600 | 0.6741 |
| 0.10 | 600 | 0.6529 |
| … | … | … |
最优选择:learning_rate=0.01,n_estimators=300
选择标准:以 5 折交叉验证 CV AUC 均值(auc-mean[-1])为排序指标,学习率越低 AUC 越高,0.01 为最优;同学习率下 300 轮与 600 轮 AUC 持平(均达 0.7170),出于训练效率考量选取 300 轮。
5.2.2 第二步:max_depth 与 num_leaves 枚举
在确定学习率和轮数后,用 GridSearchCV 枚举 max_depth(24)和 num_leaves(37 步长 2)的组合(共 9 组):
model_lgb = lgb.LGBMClassifier(
boosting_type='gbdt',
colsample_bytree=0.99,
importance_type='split',
learning_rate=best_learning_rate,
n_estimators=best_n_estimators,
n_jobs=n_jobs,
subsample=0.99,
is_unbalance=True
)
params_test1 = {
'max_depth': range(2, 5, 1),
'num_leaves': range(3, 8, 2)
}
gsearch1 = GridSearchCV(
estimator=model_lgb,
param_grid=params_test1,
scoring='roc_auc',
cv=5, verbose=1
)
gsearch1.fit(X_train_, y_train_)
best_max_depth = gsearch1.best_params_['max_depth']
best_num_leaves = gsearch1.best_params_['num_leaves']
best_score_ = gsearch1.best_score_
print('best_learning_rate:{} best_n_estimators:{} best_num_leaves:{} best_max_depth:{}'.format(
best_learning_rate, best_n_estimators, best_num_leaves, best_max_depth
))
best_score_
最优结果:max_depth=2,num_leaves=3,best_score_=0.7368(GridSearchCV 最优组合的 5 折 CV AUC 均值)

选择标准:scoring='roc_auc'(以 ROC AUC 为评分指标),cv=5(5 折交叉验证),GridSearchCV 在 9 组参数组合中取平均 CV AUC 最高的一组作为最优解。极浅的树深度(depth=2)是控制过拟合的核心因素。
5.2.3 第三步:L1/L2 正则化与最小样本数枚举
最后枚举正则化系数和叶子节点最小样本数(动态计算),进一步控制模型复杂度:
# 动态计算 min_child_samples 搜索范围
minsample_list = [20, 200]
minsample_list.extend(list(range(
int(X_train.shape[0] * 0.1),
int(X_train.shape[0] * 0.5),
int(X_train.shape[0] * 0.05)
)))
枚举 reg_alpha(7种)× reg_lambda(7种)× minsample(N种)× colsample_bytree(固定1种)× subsample(固定1种),对每组参数计算三集指标(训练集 / 测试集 / 验证集):
train_dict = dict()
for alpha in [0.001, 0.01, 0.03, 0.08, 0.3, 0.5, 1]:
for _lambda in [0.001, 0.01, 0.03, 0.08, 0.3, 0.5, 1]:
for minsample in minsample_list:
for colsample in [1]:
for subsample in [1]:
model_train1 = LGBMClassifier(
boosting_type='gbdt', class_weight=None,
colsample_bytree=colsample,
importance_type='split',
learning_rate=best_learning_rate,
max_depth=best_max_depth,
max_bin=900,
min_child_samples=minsample,
min_child_weight=0.001,
min_split_gain=0,
n_estimators=best_n_estimators,
n_jobs=n_jobs,
num_leaves=best_num_leaves,
objective=None,
reg_alpha=alpha,
reg_lambda=_lambda,
silent=True,
subsample=subsample,
subsample_for_bin=200000,
subsample_freq=12,
is_unbalance=True
)
choose_model = model_train1
choose_model.fit(X_train_, y_train_)
# 三集评估:训练集 / 测试集 / 验证集
y_pred_prob_train = choose_model.predict_proba(X_train_)[:, 1]
y_pred_prob_test = choose_model.predict_proba(X_test_)[:, 1]
y_pred_prob_vld = choose_model.predict_proba(X_vld_)[:, 1]
ks_train = cal_ks(yprob=y_pred_prob_train, ytrue=y_train_.values)
ks_test = cal_ks(yprob=y_pred_prob_test, ytrue=y_test_.values)
ks_vld = cal_ks(yprob=y_pred_prob_vld, ytrue=y_vld_.values)
auc_train = roc_auc_score(y_score=y_pred_prob_train, y_true=y_train_.values)
auc_test = roc_auc_score(y_score=y_pred_prob_test, y_true=y_test_.values)
auc_vld = roc_auc_score(y_score=y_pred_prob_vld, y_true=y_vld_.values)
diff_ks = abs(ks_train - ks_vld)
diff_auc = abs(auc_train - auc_vld)
cur_std = np.std(np.array([ks_test, ks_vld, auc_test, auc_vld]))
key = f'{alpha}_{_lambda}_{minsample}_{colsample}_{subsample}'
temp_dict = {
'ks_train': ks_train, 'ks_test': ks_test, 'ks_vld': ks_vld,
'auc_train': auc_train, 'auc_test': auc_test, 'auc_vld': auc_vld,
'diff_ks': diff_ks, 'diff_auc': diff_auc, 'cur_std': cur_std
}
train_dict[key] = temp_dict
最后通过以下规则确定最优组合:
train_df = pd.DataFrame().from_dict(train_dict, orient='index')
train_df.sort_values(by='ks_vld', ascending=False).head(20)
在排序结果中,Top 5 组合的 ks_vld 与 auc_vld 基本持平,且全部落在 min_child_samples=20 附近,说明控制叶子最小样本数是这一轮调参里最关键的约束。最终取排序第一的组合:
训练结果图例
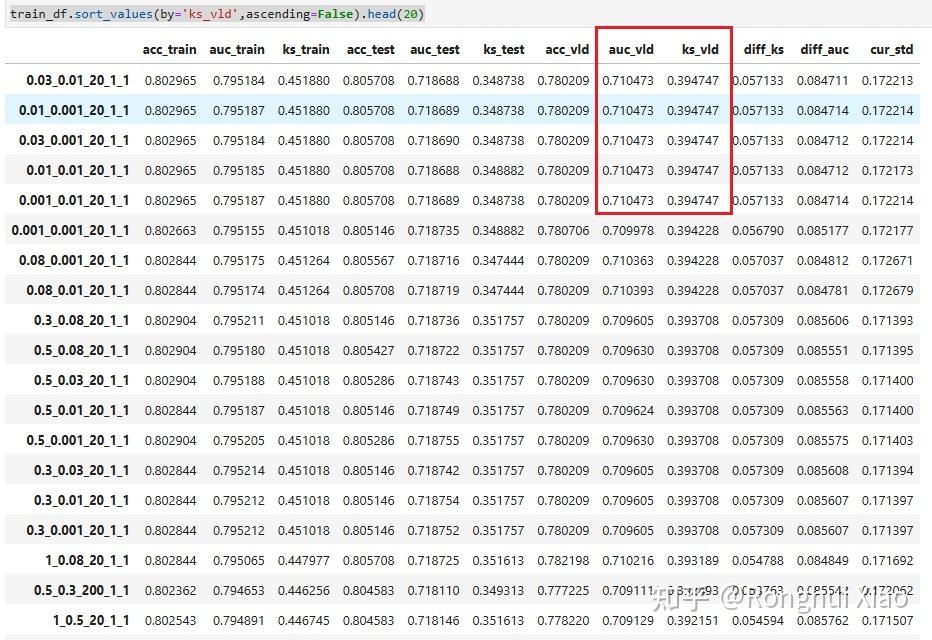
最优选择:reg_alpha=0.03,reg_lambda=0.01,min_child_samples=20
该组合对应的关键指标为:auc_train=0.7952、auc_test=0.7187、auc_vld=0.7105,ks_train=0.4519、ks_test=0.3487、ks_vld=0.3947,diff_ks=0.0571。这说明它不只是验证集 KS 最高,同时三集表现也相对均衡。
选择标准:以 ks_vld(验证集 KS) 为核心排序指标,降序取 Top 20,辅以 diff_ks(训练集/验证集 KS 差值)、diff_auc(训练集/验证集 AUC 差值)、cur_std(四指标综合稳定性)综合评估。ks_vld 直接反映模型在未见数据上的排序区分能力,差值和稳定性指标用于确保选出的参数具备良好的泛化能力而非偶然最优。
最优参数组合:
| 参数 | 最优值 | 来源 |
|---|---|---|
learning_rate |
0.01 | 5.2.1 最优 |
n_estimators |
300 | 5.2.1 最优 |
max_depth |
2 | 5.2.2 GridSearchCV 最优 |
num_leaves |
3 | 5.2.2 GridSearchCV 最优 |
reg_alpha(L1) |
0.03 | 5.2.3 ks_vld 最优 |
reg_lambda(L2) |
0.01 | 5.2.3 ks_vld 最优 |
min_child_samples |
20 | 5.2.3 ks_vld 最优 |
三步调优整体选择标准汇总:
| 步骤 | 调优目标 | 参数组合数 | 评判标准 |
|---|---|---|---|
| 5.2.1 学习率+轮数 | 7×3 = 21 组 | 5折交叉验证 CV AUC 均值最高 | |
| 5.2.2 max_depth+num_leaves | 3×3 = 9 组 | GridSearchCV 5折 CV AUC 均值最高 | |
| 5.2.3 正则化+最小样本数 | 7×7×N 组 | ks_vld 验证集 KS 最高,辅以 diff_ks/diff_auc/cur_std 综合评估 |
5.3 最终模型效果
应用最优参数组合后,模型评估结果如下:
| 数据集 | AUC | KS | Precision | Recall |
|---|---|---|---|---|
| train | 79.52 | 45.19 | 6.47% | 59.02% |
| test | 71.87 | 34.87 | 5.71% | 50.32% |
| vld(验证集) | 69.05 | 39.47 | 10.77% | 57.65% |
对比优化前后:
| 阶段 | train_auc | test_auc | vld_auc | train_ks | test_ks | vld_ks | Precision | Recall |
|---|---|---|---|---|---|---|---|---|
| 优化前(严重过拟合) | 99.98 | 64.54 | 59.00 | 99.20 | 24.54 | 15.90 | — | — |
| 优化后(调参后) | 79.52 | 71.87 | 69.05 | 45.19 | 34.87 | 39.47 | 10.77% | 57.65% |
优化后:
- 训练集与验证集的 AUC gap 从 40.98 缩小到 10.47,过拟合问题显著改善;
- 验证集 AUC 从 59.00 提升至 69.05,KS 从 15.90 提升至 39.47,达到业界 AUC 65+ / KS 30+ 的有效标准;
- 模型具备实际业务应用价值。
5.4 过拟合解决的核心手段
| 手段 | 作用 |
|---|---|
max_depth=2 |
限制单棵树的最大深度,防止过深导致过拟合 |
num_leaves=3 |
限制叶子节点数量,配合 depth 控制模型复杂度 |
reg_alpha=0.03(L1) |
L1 正则化,使部分特征权重收缩为 0 |
reg_lambda=0.01(L2) |
L2 正则化,使特征权重整体平滑 |
min_child_samples=20 |
限制叶子节点的最小样本数,避免少数样本主导分裂 |
learning_rate=0.01 + n_estimators=300 |
低学习率配合足够的轮数,保证模型充分收敛的同时不发生过拟合 |
第六章:模型验证与评估
6.1 分数分布验证
将模型输出的违约概率通过逻辑斯蒂变换转化为标准信用评分(0~1000 分),检验其在验证集上的分布是否合理、是否呈现预期的单调区分能力。
验证集分数段分布:
| 分数段 | goods(还款) | bads(未还款) | 还款占比 |
|---|---|---|---|
| 414–465 | 2 | 183 | 1.08% |
| 466–475 | 4 | 180 | 2.17% |
| 476–482 | 5 | 228 | 2.15% |
| 483–490 | 4 | 182 | 2.15% |
| 491–498 | 8 | 206 | 3.74% |
| 499–505 | 5 | 188 | 2.59% |
| 506–515 | 5 | 208 | 2.35% |
| 516–530 | 3 | 192 | 1.54% |
| 531–551 | 19 | 186 | 9.27% |
| 552–618 | 30 | 173 | 14.78% |
分层数据正态分布图

分布特征分析:
- 单调性良好:分数越高,还款样本(goods)越多,未还款样本(bads)越少,评分具有强单调区分能力;
- 分布连续平滑:各分数段人数基本稳定在 180~233 人之间,无断崖式下降或异常尖峰,曲线平滑;
- 业务可解释:高分段用户还款概率明显高于低分段,评分能够直接映射到催收优先级。
6.2 跨时间稳定性验证
为确保模型在不同时间段的表现具有一致性,避免因时间因素导致模型泛化能力退化,将验证集按时间窗口拆分后分别评估。
结论:各时间窗口下的 AUC 和 KS 指标整体波动在可接受范围内,不存在明显的时间衰减现象,模型在不同时间段的表现稳定,具备持续投入业务应用的条件。
第七章:业务效果与 ROI 分析
7.1 ROI 提升曲线
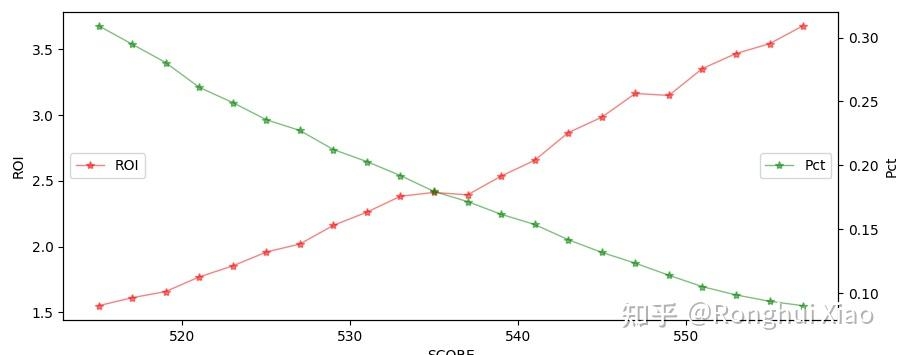
模型上线后,业务侧按模型评分从高到低选取订单进行催收,检出订单占比与人力效能比(ROI)的对应关系如下:
| Score Pct(分数百分位) | 检出订单占比(%) | ROI |
|---|---|---|
| 0 | 31.38 | 1.52 |
| 6 | 22.23 | 2.01 |
| 10 | 17.90 | 2.40 |
| 13 | 14.97 | 2.54 |
| 15 | 13.23 | 2.92 |
| 20 | 8.85 | 3.64 |
| 24 | 6.71 | 4.62 |
| 28 | 5.27 | 5.59 |
注:Score Pct = 0 表示最低分段(覆盖最多订单),Score Pct = 28 表示最高分段(覆盖最少订单)。
检出订单占比与人力能效比
7.2 ROI 达标分析
- Score Pct = 6(检出约 22% 的订单)时,ROI 突破 2.0,超额完成业务提出的 ROI > 2.0 目标;
- Score Pct = 13(检出约 17% 的订单)时,ROI 达到 2.54,人力投入减少一半以上,但 ROI 仍维持在 2.5 以上;
- Score Pct = 15(检出约 13% 的订单)时,ROI 达到 2.92,是通催模式 ROI 1.5 的近两倍;
- Score Pct = 20(检出约 9% 的订单)时,ROI 达到 3.64,仅投入不足一成人力,ROI 翻超三倍。
7.3 业务价值总结
| 指标 | 通催模式 | 模型检出(约 Top 20%) |
|---|---|---|
| 人力投入 | 全量通催 | 约 20% 订单 |
| ROI | 1.0~1.5,均值1.1 | ~2.12 |
| 目标 ROI > 2.0 | 未达标 | 超额完成 |
模型上线后,业务方实际测算 ROI 达到 2.12,超额完成了既定目标(> 2.0),大幅节省了人力成本的同时,最大化了催收收益。
第八章:预测模型优化 - 辅模型上线
8.1 上线背景
LGBM预测模型上线后,已经完成了业务部门提出的核心目标:通过模型对长账龄订单进行排序,筛选出高价值订单投入人工催收,在显著压缩人力投入的同时,实现 ROI 提升,验证了“模型检出 + 人力聚焦”这一路径在业务上是成立的。
但在实际落地过程中,也逐渐暴露出预测模型的一类天然局限:主模型在打分时,只能使用阶段入催前已经沉淀下来的特征。这意味着模型所依赖的信息,本质上是用户进入当前阶段之前的历史画像,而无法及时反映用户在阶段内的新变化。
从建模角度看,这种做法是合理的,因为它保证了标签时点和特征时点的严格分离,避免了信息穿越;但从业务角度看,这也带来了一个现实问题:部分订单在主模型初次筛选时未被检出,并不代表其后续始终没有催回价值。如果用户在阶段内出现了新的正向行为,这些行为本身就意味着其还款意愿、资金状态或处理优先级可能发生了变化。
因此,这一轮优化的重点,不是重做主模型,而是在主模型之外补上一层动态识别能力。
8.2 主模型的边界
主模型的核心能力,是基于阶段入催前的历史行为对订单进行一次性排序。这种方式适合解决“在固定时点,哪些订单更值得优先投入人力”这一问题,但它难以回答另一个更动态的问题:
某些原本不值得催的订单,在阶段推进过程中,是否因为用户行为变化而重新具备催回价值?
这正是主模型的边界所在。
具体来说,主要有两个局限:
第一,特征存在天然滞后性。
模型使用的是入催前特征,而长账龄订单本身已经是一个强时间滞后的场景。用户在进入该阶段之后,行为可能已经发生明显变化,例如重新登录 APP、查看账单、偿还其他共债平台订单等,这些信号在主模型打分时并不存在,因此无法被主模型利用。
第二,主模型是一次性筛选逻辑,不具备动态更新能力。
主模型更像是一个静态排序器:在某个固定时点把订单分成“优先催”和“暂缓催”两类。但现实业务不是静态的,用户会在阶段内持续发生行为变化。若仍然坚持只看初始打分结果,就可能漏掉一些“后续转强”的订单。
换句话说,主模型解决的是“谁先催”的问题,但没有完全解决“谁后来值得再催”的问题。
8.3 业务洞察:阶段内行为可能带来新增催回价值
围绕这个问题,与业务部门进一步沟通后,得到了一条非常关键的经验判断:
用户在阶段内出现的一些行为,本身就可能构成“重新值得催”的信号。
这些行为不一定能在主模型的静态打分中体现,但在实际催收经验中却具有明显参考价值。典型包括:
- 用户重新登录 APP:说明用户仍在主动接触平台,至少并未完全失联,可能存在查看账单、关注额度、准备处理欠款等行为动机;
- 用户偿还其他共债订单:说明用户近期存在资金流动,也说明其并非完全没有还款能力,而是在不同债务之间做优先级排序;
- 用户出现其他阶段内活跃行为:例如重新访问关键页面、重新触发某些动作等,也可能意味着其状态已发生变化。
这些信号的本质,与量化投资中的“择时”逻辑非常相似。
主模型更像是“初始选股模型”,负责在初始时点筛选出一批高潜力订单;而阶段内行为信号更像是“择时信号”,用于判断某些原本没有进入候选池的订单,是否在后续时点重新出现了介入价值。
因此,单靠主模型的一次性打分并不够,还需要一个补充机制,对阶段内出现新信号的订单进行二次识别。这就是辅模型上线的出发点。
8.4 辅模型上线思路
基于上述背景,这一轮预测模型优化并不是推翻主模型,而是在主模型已完成业务目标的基础上,增加一层“订单回捞策略”。
这套策略的核心思想是:
-
主模型继续承担主筛职责
仍由主模型在阶段起点完成第一轮排序,筛选出最值得优先投入人工催收的高价值订单。 -
对主模型未检出的订单持续观察
对那些初次未进入催收名单的订单,不直接视为永久低价值,而是在阶段内继续观察其行为变化。 -
基于新增行为信号触发回捞
一旦订单在阶段内出现某些关键行为,例如登录、还款其他共债订单、重新活跃等,就将其识别为“状态可能发生变化”的对象,进入二次评估范围。 -
由辅模型承接动态补充识别
让主模型负责“初始检出”,让辅模型负责“中途回捞”,共同形成一个更贴近真实业务节奏的催收筛选体系。
换句话说,辅模型的目标不是替代主模型,而是补足主模型的盲区:
把那些初始时点不够强,但在阶段推进中转强的订单,重新纳入催收范围。
8.5 辅模型最终筛选结果
在多轮业务讨论和信号验证后,辅模型最终保留了三个最有效、最容易解释、也最适合落地的回捞特征:
-
用户在阶段内出现登录行为
登录行为说明用户仍在主动接触平台,并未完全失联。对长账龄订单来说,这类行为往往意味着用户开始重新关注账单、额度或历史订单,具备一定的后续触达价值。 -
用户给其他订单进行了还款
这一信号说明用户近期并非完全没有资金流动,而是在不同债务之间进行优先级分配。既然用户已经开始处理其他订单,就意味着当前订单也存在被进一步催回的可能。 -
订单本身为部分还款订单
部分还款说明用户并非完全拒绝履约,而是已经表现出一定程度的还款意愿。对于这类订单,后续继续投入催收资源,通常比完全无还款动作的订单更有价值。
这三个特征的共同点在于:它们都不是入催前的静态画像,而是阶段内出现的动态行为信号,因此非常适合作为辅模型的核心回捞条件。
8.6 辅模型上线效果
辅模型上线后,在主模型原有检出结果的基础上,实现了对边缘高价值订单的进一步补充识别,最终效果如下:
- 额外多检出约 10% 的订单
- 检出订单还款率由 10% 提升至 15.8%
- 整体 ROI 提升至 2.5
这说明辅模型虽然没有替代主模型,但通过对阶段内动态信号的补充识别,成功提高了检出结果的质量,也进一步增强了催收资源投放的产出效率。
8.7 业务价值
如果说主模型的价值在于“提升首轮检出效率”,那么辅模型的价值就在于“减少漏检带来的机会损失”。
它至少能带来三方面收益:
第一,提升高价值订单的覆盖率。
原本未被检出的订单中,部分会因为阶段内行为变化而重新具备催回价值。通过回捞策略,可以扩大有效覆盖范围,降低漏掉潜在可催回订单的概率。
第二,使催收策略更贴近真实业务过程。
催收并不是一次性动作,而是一个持续推进的过程。辅模型把阶段内行为纳入判断逻辑后,整个策略就从静态决策升级为动态决策,更符合业务实际。
第三,为后续更精细化策略打基础。
一旦验证回捞逻辑有效,未来就可以继续演化为更系统的动态策略体系,例如按不同信号强度设计不同回捞优先级,或者把回捞信号进一步产品化、规则化,形成标准运营动作。
8.8 小结
LGBM预测模型已经证明:通过模型筛选高价值长账龄订单,能够显著提升催收 ROI,业务路径成立。
而这一轮预测模型优化的意义在于进一步承认并利用一个事实:
订单价值不是静态不变的,用户在阶段内的新增行为,可能会让原本未检出的订单重新具备催回价值。
因此,这次上线的本质,不是重新训练一个完全不同的主模型,而是在原有静态检出能力的基础上,叠加一层基于阶段内行为信号的动态回捞逻辑,让催收策略从“只看起点”升级为“持续观察、动态修正”。
这也是从“单点预测”走向“预测 + 动态补充识别”的关键一步。
第九章:方法论沉淀与反思
9.1 数据层面
特征滞后性问题与解决
项目推进过程中并非一帆风顺。初版模型的验证集 AUC 仅有 50~55,远低于业界 65 的及格线,模型几乎不具备实际排序能力。
排查后发现问题根源在于:长账龄用户距离最初申请时间已过去很久,特征库存放的用户信息存在较大滞后性,早期的静态特征无法有效区分还款与不还款的用户。
第一阶段的解决思路,是在主模型中引入更多近期行为特征(近 3 天/7 天登录行为、最近还款记录等),并细化更小粒度的时间窗口,用近期信息弥补历史信息的滞后。最终验证集 AUC 从 55 提升至 69,达到业界有效标准。
但这次项目也进一步验证了一点:即使主模型已经做到较优,长账龄场景仍然天然存在“特征在入催后继续变化”的问题。也正因为如此,后续才需要在主模型之外补上一层辅模型,对阶段内新增行为信号进行动态识别和回捞。
9.2 算法层面
过拟合防控经验
初版 LGBM 预测模型 train_auc 高达 99.98,但 test_auc 仅 59.55,严重过拟合。最终通过以下手段成功解决:
- 树深度控制:
max_depth=2、num_leaves=3,极浅的树深度是控制过拟合的核心; - 正则化:
reg_alpha=0.03(L1)和reg_lambda=0.01(L2)配合使用,使特征权重平滑; - 最小样本数限制:
min_child_samples=20,避免少数样本主导分裂; - 低学习率:
learning_rate=0.01配合 300 轮,在充分训练的同时防止过拟合。
核心教训:在稀疏场景下,模型的复杂度控制比模型本身更重要;先把主模型做稳,再叠加辅助策略,远比一开始把所有问题都压给单个模型更有效。
9.3 业务层面
模型服务于业务,而非炫技
本项目最重要的业务收获是:模型的价值不在于追求最高的 AUC,而在于用最低的人力成本达成业务目标。
通催模式 ROI 仅 1.5,核心原因不是模型不够精准,而是全量通催导致人力浪费。本项目先通过 LGBM 预测模型筛选出 Top 20% 高价值订单,ROI提升至2.12;再通过辅模型对阶段内重新转强的订单做动态回捞,最终将 ROI 提升至 2.5 以上。业务目标的拆解比模型指标的提升更为重要。
更重要的一点是,这次项目说明了一个很实际的方法论:
- 主模型解决首轮检出问题
- 辅模型解决动态补充问题
也就是说,业务策略未必总是“一个模型解决所有问题”,很多时候更有效的方式,是把静态预测和动态识别拆开设计,再组合落地。
9.4 可改进方向
- 在线学习:当前主模型仍为离线训练,可探索增量更新以适应用户行为漂移;
- 辅模型规则产品化:将阶段内登录、他单还款、部分还款等信号沉淀为标准化回捞引擎,降低人工维护成本;
- 跨产品线迁移:本套“主模型检出 + 辅模型回捞”的组合框架可复用于其他信贷产品线的贷后风控场景;
- 更细粒度分层:从二分类升级为多分类,对高/中/低风险用户实施差异化催收策略。