Background
After deploying OpenClaw to a cloud server and connecting it to Feishu, a single agent was already creating real value in my day-to-day data work. Once the asset analysis Skill went live, I no longer needed to run SQL queries manually. I could simply send a query instruction to the AI in Feishu and receive formatted metric results. At the beginning, that experience significantly improved my efficiency.
As business needs expanded, however, I started connecting the conversion analysis Skill and the collection analysis Skill to the same agent. Problems followed quickly: when handling queries across multiple business lines, the AI began to show what I would call “memory confusion.” It would occasionally apply asset data definitions to conversion analysis by mistake, or lose track of the original task after several turns of conversation. Limits in context length, Skill scheduling conflicts, and reduced task focus all became increasingly obvious. The bottlenecks of a single-agent setup were now clear.
The root problem was not that the model itself was incapable. The limitation was architectural. When a single agent faces complex tasks spanning multiple business lines and dimensions, its context window and task scheduling capacity have a natural upper bound. That led me to a new question: could I split different business lines into independent agents, let each one focus on a single domain of analysis and decision-making, and then rely on collaboration between them to solve more complex multi-dimensional tasks?
Moving from a single agent to a multi-agent system is not just adding more agents. It is a redesign at the architectural level. This article documents my full journey within the OpenClaw framework from a single-agent architecture to a multi-agent collaboration system, including the problems I ran into, the technical choices I made, the architecture design, the implementation plan, and the final results. I hope it can serve as a useful reference for business practitioners.
1. Why Start with a Single Agent
In the first phase of building an AI-powered data analysis assistant, I chose a single-agent architecture. That decision was not accidental. It was a pragmatic response to the business scenario and resource constraints at the time.
Quickly validating the business scenario
At the beginning of the project, the core goal was to get the asset analysis business line working as quickly as possible and verify whether the AI assistant could provide real value in day-to-day work. The advantage of a single agent is its simplicity: the architecture is straightforward, the debugging path is clear, every request flows through the same entry point, and every Skill is loaded into the same context. That let me go from zero to one in the shortest possible time, get the asset analysis Skill working, and put it into real use.
This path makes sense for any new business scenario: focus first on solving one core problem, rather than trying to design a perfect multi-agent system before the architecture has matured.
One business line was enough for daily use
When the asset analysis Skill first went online, daily query needs were concentrated in a single dimension: asset quality monitoring. The questions I needed to ask were relatively stable, including key metrics such as the D0 collection-entry rate, D0 spread, cumulative spread-to-date, bad debt ratio, and breakdowns by channel, package, and customer segment. A single agent handled this kind of structured query reliably, and the quality of the responses matched expectations.
At that stage, introducing multiple agents would only have added unnecessary complexity. Before scale and demand were fully validated, a single agent was the highest-leverage choice.
Cost and debugging efficiency came first
From a resource perspective, a single agent consumes far less context window capacity and fewer tokens than a multi-agent system running in parallel. In the early phase of the project, the data volume was limited and the number of conversation turns was manageable, so the runtime cost of a single agent stayed within an acceptable range.
From a debugging perspective, a single agent also offers a clean logging path and a short path to root cause analysis. If a Skill returned an unexpected result, I only needed to inspect the context and call history of one agent. That made troubleshooting efficient and kept iteration speed high.
2. Where the Single Agent Hit Its Ceiling
As the asset analysis Skill became more stable, I gradually connected the conversion analysis Skill and the collection analysis Skill to the same agent, hoping to create a unified query entry point across all three major business lines. In practice, the problems introduced by that expansion were more complicated than I expected.
Context-window memory confusion
Once the Skills for all three business lines were loaded into the same agent, the burden on the context window increased substantially. Consider a typical cross-domain analysis scenario: I first ask about the D0 collection-entry rate on the asset side, then switch to approval rate on the conversion side, and then ask about repayment rate on the collection side. After handling three rounds of tasks with completely different business semantics, the AI began to lose context. It reused asset-side definitions in conversion-side analysis, or confused the definitions of metrics across the two business lines.
This kind of “memory confusion” was not an occasional edge case. It happened frequently. The underlying reason is simple: the context window of a single agent had to carry the concepts, terminology, and data dictionaries of all three business lines at once. As conversations grew longer, the density of useful information rose continuously, and valuable signals were gradually diluted or overwritten.
Skill scheduling conflicts
The Skills for different business lines differed in when they should be called and in their input and output formats. When I made multiple cross-domain requests in the same conversation, the agent had to keep switching between different Skill contexts. During those switches, parameters were sometimes lost and stale state sometimes leaked across calls. For example, results produced by the asset analysis Skill could be incorrectly passed into the next calculation step of the collection Skill, causing the final output to drift away from the actual business expectation.
These conflicts were rare when only one Skill was in play, but they became increasingly obvious as the number of Skills grew.
Reduced task focus
When handling mixed tasks, a single agent had to keep switching role identities within one context. At one moment it acted as an asset analyst, then as a conversion analyst, then as a collection analyst. Those repeated identity switches consumed a large amount of context space and reduced the agent’s focus in each business line. In practice, that showed up as more generic analytical replies and less precise structured data when querying asset metrics.
Once business needs evolved from “single-line queries” to “multi-line collaborative analysis,” the architectural bottleneck of a single agent could no longer be solved by prompt tuning or minor Skill optimization. The answer had to come from the architecture itself.
3. Design Thinking Behind the Multi-Agent Architecture
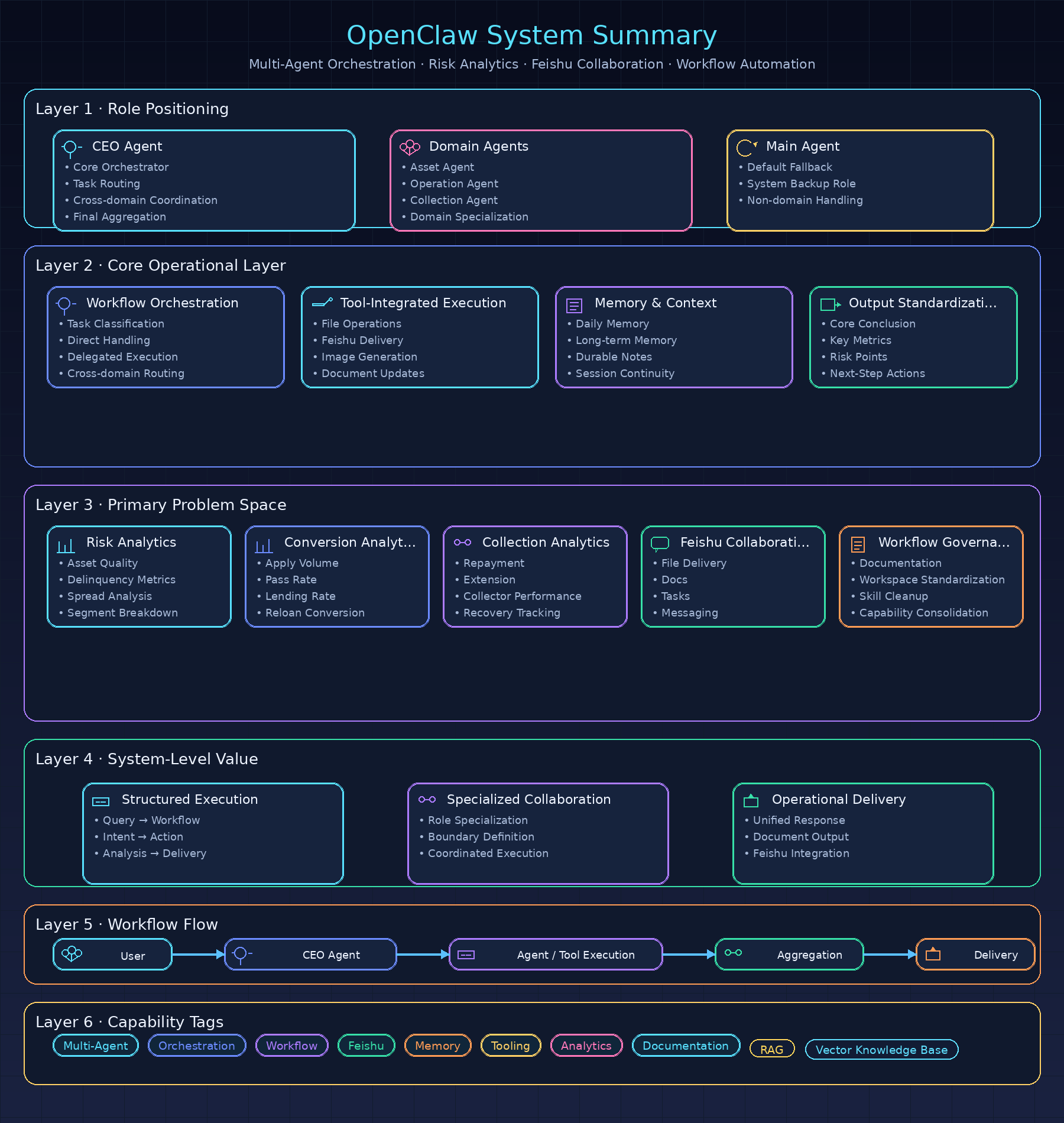
To address the architectural bottlenecks of a single agent, I designed a master-worker agent architecture with a CEO Agent serving as the coordination entry point and three specialist child agents responsible for execution.
Overall architecture
The CEO Agent (coordination entry point) serves as the unified interface for user interaction and sits at the front line of Feishu conversations. When a user submits a task in Feishu, the CEO Agent is responsible for understanding the intent, determining which business line the task belongs to, dispatching the task to the appropriate specialist child agent, and finally collecting the returned results into one unified response.
The CEO Agent has its own scheduling rules in dispatch-rules.md, which explicitly define the responsibility boundaries of each child agent and the task routing logic. It acts as the coordination hub of the entire architecture.
The asset Agent is dedicated to asset quality monitoring. It is connected to the asset analysis Skill, has its own isolated workspace and workflow conventions, and focuses on analyzing and reporting metrics such as collection-entry rate, spread, and bad debt ratio.
The operation Agent is dedicated to operational conversion analysis. It is connected to the conversion analysis Skill and focuses on analyzing and reporting metrics across the full funnel from application to disbursement, including application creation rate, submission rate, approval rate, and disbursement rate.
The collection Agent is dedicated to collection team management. It is connected to the collection analysis Skill and focuses on analyzing and reporting metrics such as collection settlement rate, extension rate, and repayment rate.
Collaboration mechanism
The CEO Agent collaborates with the three child agents through task distribution and result aggregation:
- The CEO Agent receives the user’s request in Feishu.
- It identifies the task type and routes it to the appropriate specialist child agent according to the scheduling rules (
asset,operation, orcollection). - Each child agent performs its analysis inside its own isolated workspace and returns the result to the CEO Agent.
- The CEO Agent consolidates the child-agent outputs and returns them in a unified format: key conclusion, critical data, main anomalies, which link had the biggest impact, and next-step recommendations.
Scheduling rules
The CEO Agent’s scheduling rules cover two types of scenarios:
Single-domain questions: questions about one business line are sent directly to the corresponding child agent. For example, questions involving collection-entry rate or spread go to the asset Agent, questions involving conversion rate or drawdown rate go to the operation Agent, and questions involving collection-stage performance go to the collection Agent.
Cross-domain questions: complex questions involving multiple business lines are decomposed by the CEO Agent and then dispatched to multiple child agents in parallel. For example, daily and weekly reports require coordination across all three business lines, so the CEO Agent sends them to the asset, operation, and collection agents at the same time and then produces one combined summary.
4. Technical Implementation Plan
Below is the complete configuration approach for the current multi-agent system. It can be executed directly within OpenClaw to generate the full setup automatically.
Agent configuration
Register four agents under agents.list in openclaw.json, with MiniMax configured as the fallback model for each:
{
"id": "ceo",
"name": "CEO Agent",
"workspace": "/root/.openclaw/workspace/agents/ceo/workspace",
"model": {
"primary": "openai-codex/gpt-5.4",
"fallbacks": ["minimax-portal/MiniMax-M2.7"]
}
},
{
"id": "asset",
"name": "Asset Analyst",
"workspace": "/root/.openclaw/workspace/agents/asset/workspace",
"model": {
"primary": "openai-codex/gpt-5.4",
"fallbacks": ["minimax-portal/MiniMax-M2.7"]
}
},
{
"id": "operation",
"name": "Operation Analyst",
"workspace": "/root/.openclaw/workspace/agents/operation/workspace",
"model": {
"primary": "openai-codex/gpt-5.4",
"fallbacks": ["minimax-portal/MiniMax-M2.7"]
}
},
{
"id": "collection",
"name": "Collection Analyst",
"workspace": "/root/.openclaw/workspace/agents/collection/workspace",
"model": {
"primary": "openai-codex/gpt-5.4",
"fallbacks": ["minimax-portal/MiniMax-M2.7"]
}
}
Feishu entry point configuration
The entire system has only one Feishu entry point: the CEO bot account. All user requests come in through that single account, are received by the CEO Agent, and are then routed and dispatched by it.
Directory structure
Each agent has its own isolated workspace and includes the following files:
agents/
├── ceo/
│ ├── SOUL.md # CEO role definition and scheduling rules
│ ├── dispatch-rules.md # Single-domain / cross-domain routing logic
│ ├── workflow.md # CEO workflow
│ ├── MEMORY.md # Cross-domain memory
│ └── workspace/ # CEO working directory
├── asset/
│ ├── SOUL.md # Asset analyst role definition
│ ├── workflow.md # Asset analysis workflow
│ ├── skills.md # Binds asset-metrics
│ └── workspace/
├── operation/
│ ├── SOUL.md
│ ├── workflow.md
│ ├── skills.md # Binds apply-metrics
│ └── workspace/
└── collection/
├── SOUL.md
├── workflow.md
├── skills.md # Binds collection-metrics
└── workspace/
CEO Agent scheduling rules
dispatch-rules.md defines the task routing logic:
Single-domain questions are routed directly:
- Collection-entry rate, spread, bad debt ratio, and similar metrics → asset Agent
- Approval rate, drawdown rate, conversion funnel, and similar metrics → operation Agent
- Collection recovery rate, caseR, amtR, and similar metrics → collection Agent
Cross-domain questions are routed in parallel:
- Daily reports / weekly reports → route to asset + operation + collection together
- Channel-level integrated analysis → route to asset + operation together
Unified summary output format:
Key conclusion → Critical data → Main anomalies → Which link had the biggest impact → Next-step recommendations
Skill bindings
| Agent | Bound Skill |
|---|---|
| asset | asset-metrics |
| operation | apply-metrics |
| collection | collection-metrics |
| ceo | No calculation Skill bound; only dispatching and summarization |
Task flow
User → CEO Agent (single entry point) → Determine route → Dispatch to specialist agents → Collect results → Summarize output → User
Single-domain flow: User → CEO → Corresponding specialist agent → CEO → User
Cross-domain flow: User → CEO → Multiple specialist agents in parallel → CEO summarizes → User
5. Key Challenges During Implementation and How I Solved Them
The advantages of a multi-agent architecture are easy to see in design documents, but moving from a single agent to coordinated multi-agent execution surfaced several concrete implementation challenges. I eventually found workable solutions for each of them.
Challenge 1: The tension between context isolation and context sharing
Problem
Each child agent has its own independent workspace and context. That prevents interference between agents, but it also means that shared information must be passed explicitly. If the asset Agent detects an abnormal spike in the collection-entry rate for a specific channel, that information is not automatically synchronized to the operation Agent. When the operation Agent later analyzes the conversion rate for that same channel, it will not naturally associate the result with the asset-quality anomaly.
Solution
The CEO Agent actively establishes cross-business-line correlations during the summarization step. In dispatch-rules.md, I explicitly defined the rule that “if multiple agents produce conflicting conclusions, the conflict must be called out and followed by further verification.” When a user asks a cross-business-line question, the CEO Agent proactively dispatches the task to multiple child agents and then creates the cross-domain linkage in the final summary, rather than simply concatenating independent conclusions from each agent.
Challenge 2: Defining clean Skill boundaries
Problem
Each of the three child agents is bound to a different Skill, and those boundaries must stay clear. Otherwise, responsibilities become ambiguous and duplicate calls become likely. If the metric definitions inside one Skill change, every agent that relies on that Skill must be updated consistently. Any missed update can create data inconsistency.
Solution
Each child agent has its own skills.md file that explicitly defines the Skills it is allowed to use and the usage rules around them. I enforced a rule that each agent may call only the Skills declared in its own skills.md, and may not call across agent boundaries. Any definition change is maintained within the corresponding agent’s skills.md, while the CEO Agent’s dispatch-rules.md centrally coordinates routing logic. That keeps responsibility boundaries clean at the source.
Challenge 3: Controlling the quality of child-agent outputs
Problem
In the single-agent era, I only needed to evaluate the quality of one agent’s output. In a multi-agent setup, I had to monitor the output quality of three child agents at once and then determine, during CEO-side summarization, whether there were conflicts in metric definitions or contradictions in conclusions. Early in implementation, the output formats of the agents were inconsistent, so the CEO Agent had to do additional normalization work before it could produce a unified summary.
Solution
I introduced a mandatory unified output template in output-template.md. Every child agent is required to return results in the same structure: analysis topic → key conclusion → critical data → dimensional breakdown → anomaly points → cause assessment → next-step recommendations. When the CEO Agent receives results from child agents, it first checks whether the format is compliant. Non-compliant outputs are rejected and recomputed. That guarantees consistency in the final aggregated report.
6. Results and Comparison
After the multi-agent architecture went live, I ran a systematic evaluation of its performance in everyday business scenarios, focusing on the differences between the single-agent and multi-agent approaches across several core dimensions.
Context memory capability
With a single agent, the context window gradually accumulates the concepts and terminology of all three business lines across multiple conversation turns. As the conversation gets longer, the density of useful information drops, and the AI starts to lose context. It may incorrectly apply asset-side definitions to conversion scenarios, or forget the original analytical objective after a long exchange.
With multiple agents, each child agent has its own isolated context with no cross-interference. The asset Agent carries only asset-analysis-related content, while the operation Agent carries only conversion-analysis-related content. That isolation keeps each agent’s context dense and focused, rather than diluted as business lines are added. In actual testing, even after 20 consecutive rounds of cross-business-line conversation, each child agent could still accurately understand the goals within its own domain.
Task focus
With a single agent, mixed tasks require frequent identity switching: from asset analyst to conversion analyst to collection analyst. Those switches consume a large amount of context space and reduce the AI’s focus in each business line, leading to more generalized analytical replies and fewer precise data outputs.
With multiple agents, each child agent is locked to a single role, and focus improves significantly. The asset Agent remains an asset analyst, the operation Agent remains a conversion analyst, and the collection Agent remains a collection analyst. In actual testing, all three child agents produced more precise outputs than the single-agent system did, with better completeness and accuracy in structured data.
Cross-business-line analysis capability
A single agent handling cross-domain questions such as “Why is conversion good in this channel while asset quality is poor?” must process multiple analytical logics in a single context, which makes definition confusion and data mismatches much more likely.
In a multi-agent setup, the CEO Agent receives the cross-domain question, dispatches it to multiple child agents in parallel, and lets each child agent complete its analysis in its own isolated context. The results are then merged back by the CEO Agent. In actual testing, the quality of cross-business-line analysis was clearly better than in the single-agent setup, and the CEO Agent was able to establish accurate cross-domain correlations during summarization.
Response time
With a single agent, all tasks are processed inside one context, so the execution path is shorter and response time for a single question is slightly lower than in a multi-agent setup.
With multiple agents, the CEO dispatch step and result aggregation step add overhead, so single-domain questions are slightly slower. However, cross-domain questions become faster overall because multiple child agents can execute in parallel instead of being handled serially by one agent.
Scheduling reliability
A single agent has simpler routing logic and a lower chance of routing errors, but it cannot handle complex collaborative tasks across business lines.
With multiple agents, dispatch-rules.md provides standardized task routing logic. Single-domain questions are routed directly to the corresponding child agent, while cross-domain questions are decomposed and dispatched centrally by the CEO Agent. Once the routing rules are codified in a file, the debugging and iteration path becomes clear. When routing errors occur, I can trace them directly to the relevant rule entry.
7. Example Application Scenario
The practical value of a multi-agent architecture ultimately has to be validated in a real business scenario. The following example shows a full weekly business report workflow and demonstrates how the CEO Agent coordinates three specialist child agents to complete the task together.
Demo overview
This scenario simulates an ordinary weekly report generation workflow. It requires the CEO Agent to coordinate the Asset, Operation, and Collection specialist agents to produce a joint result. All metric names, dimension names, and data sources come from the actual data warehouse fields used by each agent. The purpose is to demonstrate multi-agent division of labor, data warehouse mapping capability, and report generation capability.
Collaboration flow
The weekly report is generated through the following workflow:
User submits a weekly report request → CEO Agent decomposes and dispatches the task → Three child agents execute in parallel → CEO Agent validates and summarizes → Final weekly report is returned
The responsibilities of each agent are as follows:
The CEO Agent confirms the reporting period, breaks the request into subtasks, defines the unified delivery structure, and performs final consistency checks on time definitions, field definitions, and metric naming.
The Asset Agent uses the asset-metrics Skill to query the nigeria_asset.asset_data data source and generate disbursement scale, average ticket size, collection-entry metrics, spread metrics, and dimensional breakdowns.
The Operation Agent uses the apply-metrics and operation-data-metrics Skills to query nigeria_asset.apply_data and nigeria_asset.operation_data, and generates metrics for applications, approvals, drawdowns, and conversion funnels.
The Collection Agent uses the collection-metrics Skill to query nigeria_asset.nigeria_collection_data, and generates post-loan metrics such as recoveries, extensions, settlements, caseR, and amtR.
Sample core conclusions from the weekly report
The final weekly report includes the following key conclusions:
Disbursement scale: This week’s recovery in disbursement scale was driven mainly by returning customers and deferred returning customers; pure new customers still did not become the primary growth engine.
Conversion: Approval rates for front-loaded and back-loaded pure new customers remained weak, while returning customers and repeat returning customers delivered much better conversion efficiency.
Assets: Asset quality for new customers remained weaker than for returning customers. Differences across package groups and RG tiers were significant, and the shared-debt dimension had a particularly strong impact on repeat-loan assets.
Post-loan: Collections in the D0 and S1 stages were relatively strong, but amount recovery at S3+ remained under pressure, and later-stage company performance showed clear divergence.
Full demo document
The full weekly report demo, including detailed data charts, definition notes, and validation records for each business line, is available here:
8. Conclusion
This article documents the full path of my evolution from a single-agent setup to a multi-agent collaboration system.
Starting point: At the end of February this year, I completed the OpenClaw deployment and Feishu integration, and the asset analysis Skill officially went live. Every day, I could send query instructions to the AI in Feishu and receive formatted metric results, which significantly improved data-observation efficiency.
Bottleneck: As business needs expanded, I gradually connected the conversion analysis and collection analysis Skills to the same agent. Problems followed quickly: memory confusion in the context window, Skill scheduling conflicts, and declining task focus. The architectural bottleneck of a single agent in a multi-business-line scenario became unmistakable.
Solution: I designed a master-worker architecture with the CEO Agent as the coordination entry point and three specialist child agents (asset, operation, and collection) responsible for execution. The CEO Agent receives Feishu requests through one unified interface, routes tasks to the appropriate child agents using the rules defined in dispatch-rules.md, and then aggregates the results back into a unified response according to the standardized output template.
Implementation outcome: After the multi-agent architecture went live, context memory, task focus, and cross-business-line analytical capability all improved significantly compared with the single-agent setup. During implementation, I addressed three key challenges by standardizing dispatch-rules.md and output-template.md: context isolation versus sharing, clean Skill boundary definition, and output quality control.