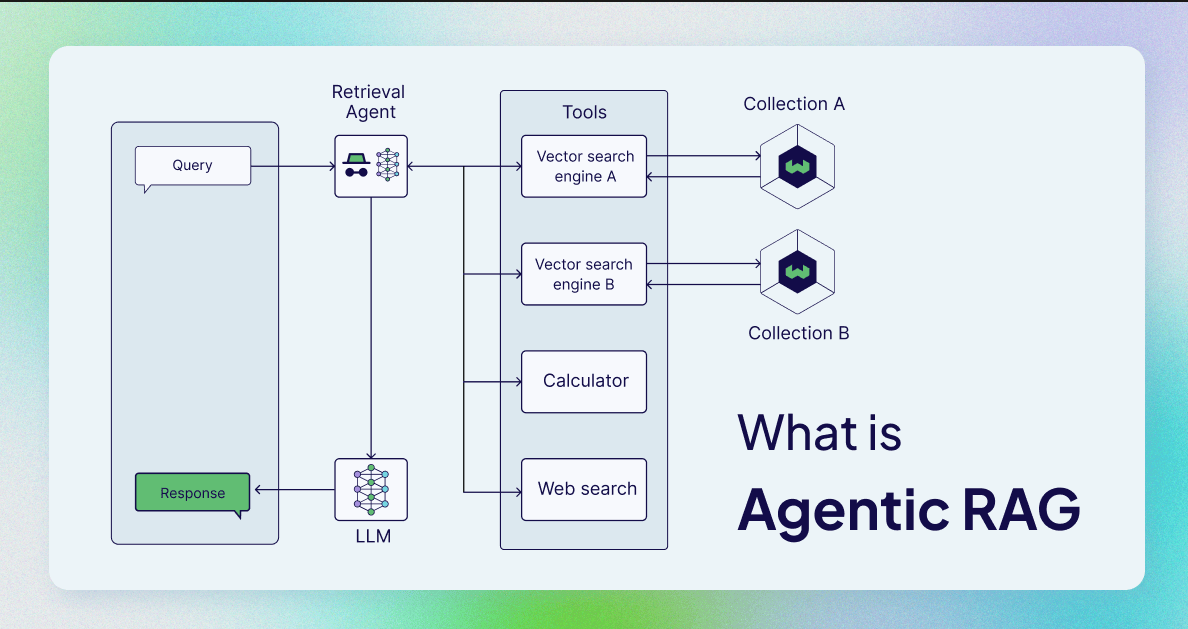
Chapter 1: RAG Fundamentals
1.1 What Is RAG
RAG (Retrieval-Augmented Generation) is a technical architecture that combines information retrieval with large language model generation. The core idea is simple: instead of letting an LLM make up an answer from thin air, first retrieve relevant passages from an external knowledge base, then generate the answer based on those passages.
Take a typical example. A user asks, “How do you calculate the D0 collection-entry rate?” A standard LLM might answer, “Roughly overdue orders divided by total orders,” which is vague and may be wrong. A RAG system first retrieves the exact definition from the metric dictionary, such as “D0 order collection entry = 1 - dpd0_repay / dpd0_cnt,” and then generates an accurate answer from that evidence. The answer becomes traceable, the definition can be verified, and hallucinations are reduced significantly.
1.2 Core Components
A RAG system has five core stages:
1. Chunking: Split long documents into smaller passages suitable for retrieval. Chunk quality directly determines retrieval quality. Common strategies include splitting by heading hierarchy, by paragraph, or by a fixed character count. If chunks are too large, they introduce noise and may exceed context limits; if too small, they lose contextual relationships.
2. Embedding: Map text into dense vectors so semantically similar text ends up close in vector space. Embeddings are the foundation of vector retrieval and define how well the system understands meaning. Common models include OpenAI’s text-embedding-3 family (strong quality but paid), BGE-small-zh (open-source and CPU-friendly), and m3e-base (good for Chinese).
3. Retrieval: Given a user query, retrieve the most relevant top-k passages from a vector database or index. Retrieval is the heart of RAG because it determines what knowledge the LLM gets to see.
| Method | Principle | Strengths | Weaknesses |
|---|---|---|---|
| BM25 | Term frequency + inverse document frequency | No embedding model required, runs locally, strong on domain-specific terminology | Cannot handle synonyms or semantic similarity well |
| Vector retrieval | Semantic vector similarity | Understands meaning, supports synonym matching | Requires an embedding model and vector database |
| Hybrid retrieval | BM25 + vector fusion | Combines both strengths for broader recall | More complex to implement |
4. Prompt Assembly: Combine retrieval results, the user question, and system instructions into the LLM input. Prompt design determines whether the model behaves as intended. Common strategies include enforcing answer structure (conclusion first, evidence second), confidence constraints (say “I don’t know” when evidence is insufficient), scope boundaries (explicitly state what cannot be answered), and citation formatting (answers must include sources).
5. LLM Generation: Produce the final answer from the assembled prompt. The generation model can be deployed locally (for example, Qwen, LLaMA, or ChatGLM) or called through an API (for example, GPT-4 or Claude).
1.3 Chunking Strategies
The right chunking strategy depends on document structure and business context:
| Strategy | Principle | Best For | Potential Issues |
|---|---|---|---|
| By heading hierarchy | Split on # headings |
Markdown and structured documents | A single heading may contain no meaningful content |
| By paragraph | Split on paragraph breaks | Documents with clear paragraph structure | Paragraphs may still be too long |
| Fixed size | Hard split by character count (for example, 900 chars) | General-purpose scenarios | May break semantic units |
| Recursive splitting | Recursively split by paragraph, then sentence | General-purpose scenarios | More complex to implement |
In practice, chunk quality matters more than algorithm choice. Common optimizations include filtering out meaningless heading-only fragments, cleaning Markdown noise (list markers, numbering, code markers), filtering very short content (fewer than 40 characters), and filtering by content density (for example, chunks where heading lines account for more than 70%).
1.4 Choosing a Retrieval Strategy
Vector retrieval and BM25 are not mutually exclusive. In real systems, you can keep both and switch between them through configuration.
When BM25 works well: business documents full of domain-specific terms such as “collection-entry rate,” “spread,” or “average amount per case.” For exact-match recall, BM25 can perform as well as vector retrieval and does not require an extra embedding model, which makes it a good fit for resource-constrained environments. Its downside is weak handling of synonyms and conversational phrasing, such as “How much did they borrow?” versus “contract amount.”
When vector retrieval works well: scenarios that require stronger semantic understanding, such as knowledge bases rich in synonyms, multilingual documents, or cases where semantic ranking matters. The cost is the need for an embedding model and vector database.
A stronger setup is hybrid retrieval plus reranking: use BM25 or vector retrieval in stage one to recall the top 20 candidates quickly, then rerank them with a CrossEncoder or BGE-Rerank model and keep the top 4. This two-stage pipeline usually improves relevance substantially.
1.5 Evaluation Methods
RAG evaluation is usually split into retrieval quality and generation quality.
Mainstream Evaluation Frameworks
| Framework | Core Idea |
|---|---|
| RAGAS | Uses an LLM to score faithfulness, answer relevance, and context relevance |
| ARES | Uses an LLM as a judge and scores answers against reference answers |
| Trulens | Provides measurable dashboards for both retrieval and generation |
| LangSmith | Supports tracing and evaluation for production RAG systems, including human annotation workflows |
Retrieval-Side Evaluation
| Metric | Meaning | Evaluation Goal |
|---|---|---|
| Recall@K | Ratio of top-k results that contain the correct answer | Whether recall is comprehensive |
| MRR | Mean reciprocal rank of the correct answer | Whether the best result appears near the top |
| NDCG | Relevance-weighted ranking quality | Overall ranking quality |
Generation-Side Evaluation
| Method | Description | Limitation |
|---|---|---|
| LLM-as-Judge | Use GPT-4 or Claude to evaluate generated answer quality | Prompt-template-driven and somewhat subjective |
| BLEU/ROUGE | Automatic scoring based on n-gram overlap | Cannot judge factual correctness |
| Human evaluation | Random sampling with manual quality review | Expensive and hard to scale |
The hard part of generation evaluation is this: automated metrics such as BLEU and ROUGE only measure textual overlap. They cannot tell whether an answer is factually correct or semantically aligned. In business scenarios with high accuracy requirements, manual spot checks remain indispensable.
My RAG Evaluation Practice
Combining industry practice with practical resource constraints, I use the following approach:
- Retrieval side: quantify retrieval quality with Recall@K and MRR, and regularly inspect the relevance of the top 6 results
- Generation side: rely mainly on manual review, sampling 20 to 30 real queries in each iteration
- End-to-end: collect bad cases from real meeting-query scenarios and keep iterating on the system
1.6 Optimization Directions
RAG is a system that needs continuous iteration. Common optimization directions include:
- Retrieval side: query rewriting (make the query more retrieval-friendly), query expansion (add synonyms), hybrid retrieval plus reranking
- Generation side: Self-RAG to let the model decide whether retrieval is needed, and Corrective-RAG to detect hallucinations and retrieve again
- Knowledge-base side: layered knowledge (rank by importance or confidence), and incremental indexing (auto-update when new documents arrive)
Chapter 2: Background and Motivation
2.1 Business Context
I work as a business analyst in the lending industry. In my daily work, I rely on a multi-agent system for data analysis and report generation. Among those agents, the asset agent is the one I use most often, mainly for two core scenarios:
- Meeting-time data lookup: quickly query asset data by specific dimensions during meetings, such as collection-entry rate or spread for a given channel, package, or customer segment
- Report generation: repeatedly query data and summarize it under fixed definitions when producing daily or weekly reports
2.2 The Capabilities and Evolution of the Asset Agent
The asset agent is responsible for full-spectrum asset analysis questions: disbursement scale, collection-entry rate, spread, channel distribution, package performance, and more. In meetings, when I need to answer questions like, “What was the D0 collection-entry rate for front-loaded new customers this week, and how did it change week over week?”, the agent has to pull data from a database or Excel files, filter dimensions, calculate metrics, and present a conclusion.
The previous implementation depended on asset-analysis skills. Those skills encapsulated all definitions, metric formulas, and analysis logic in advance, and the agent would call the relevant skill based on the user’s question.
However, as the business expanded, the dimensions and metrics embedded in the skills kept growing:
| Dimension / Metric | Continuously Growing Content |
|---|---|
| Channels | Facebook / Google / TikTok / Organic / non-paid, plus 7 paid packages |
| Packages | 7 paid packages + APK packages |
| Customer segments | Existing customers / new customers (pure new / non-pure new) / multi-loan existing / multi-loan new |
| Products | Front-loaded / back-loaded × single-loan / multi-loan |
| Metrics | D-1 / D0 collection entry, D0 spread, cumulative spread, average amount per case, bad-debt rate, etc. |
| RG grades | A / B / C / D / E / F / G |
The limitations of the skills-based approach became increasingly obvious:
- Poor readability: definitions existed only as code, so callers could get results but could not directly inspect the reasoning process
- High maintenance cost: when dimensions and metrics grew, the skills code had to be updated in sync, and reuse across scenarios was hard
- Limited extensibility: when adding new analysis dimensions or handling exploratory questions, the skills structure was too rigid
That is why I needed a RAG knowledge base as a complement to skills: move descriptive knowledge such as definitions, standards, and SOPs into the knowledge base and let RAG provide question-answer retrieval, while keeping structured computation logic in skills. Each part does what it is best at.
2.3 Pressure on Knowledge Management
Even after introducing a knowledge base, managing the knowledge itself remains difficult. Asset-analysis knowledge is scattered across multiple places:
- Feishu docs: metric dictionaries, dimension definitions, analysis SOPs
- Code comments: some business logic is embedded directly in Python scripts
- DM conversations: temporary definition agreements that exist only in message history
This creates several problems:
- Inconsistent definitions: the same term may be defined differently across documents, which can lead the agent to answer inconsistently
- Unsynced updates: code logic changes, but documentation does not, causing knowledge drift
- Poor reusability: it is hard to reuse definition knowledge quickly in new scenarios such as automated report generation
- High maintenance cost: it takes too long to understand the agent’s actual capability boundaries
The number of asset-analysis dimensions and metrics will keep growing, and the complexity of knowledge management will keep rising with it. I needed a systematic knowledge-management mechanism, and that was the original driver behind RAG plus a knowledge vector store.
2.4 Why RAG
Across the industry, mainstream knowledge-management stacks have shifted toward RAG. In AI-native applications and enterprise knowledge-base Q&A scenarios, RAG has become the default architectural choice in practice:
| Approach | Industry Status |
|---|---|
| Pure document search | Last-generation approach, lacks semantic understanding |
| Hard-coded rules | Expensive to maintain, difficult to scale |
| Pure LLM memory | Limited by context window, cannot handle large knowledge sets |
| RAG | Mainstream industry solution, suitable for almost all knowledge-Q&A scenarios |
RAG’s core strengths, natural-language Q&A, updatable knowledge, and traceable answers, align exactly with the needs of fast meeting-time lookup and report generation.
As an AI application builder, I also see hands-on RAG experience as essential. My learning goal was clear: chunking strategy, retrieval pipeline, prompt constraints, and evaluation can only really be understood by building them yourself and validating them in a real asset-agent workflow.
Chapter 3: System Build Process
3.1 Overview of the Build Flow
Environment setup (install dependencies / Ollama / pull model)
↓
Configuration management (write config.yaml)
↓
Knowledge-base construction (organize markdown files)
↓
Index build (python build_index_v2.py)
↓
Start service (python app.py)
↓
Validation tests (/health → /search → /ask)
3.2 Environment Setup
Python dependencies: fastapi uvicorn pydantic pyyaml jieba rank_bm25 chromadb requests
Ollama model: use ollama pull qwen2.5:0.5b. One model serves two purposes, both embedding and generation, which saves resources.
3.3 Project Structure
asset_rag/
├── app.py # FastAPI service, core inference logic
├── build_index_v2.py # Index build script
├── config.yaml # All configurable parameters
├── prompt.md # System prompt template
├── index.json # BM25 index (generated after build)
└── chroma_db/ # Vector database (when vector mode is enabled)
asset_knowledge_base/ # Knowledge base, separate from the service
├── 01_metric_definitions/
├── 02_dimension_definitions/
├── 03_data_dictionary/
└── 04_analysis_sop/
Design idea: keep the knowledge base independently maintained, and let the service pick up new knowledge automatically after the index is rebuilt.
3.4 Configuration Management
Centralize all parameters in config.yaml:
ollama_base_url: http://127.0.0.1:11434
ollama_model: qwen2.5:0.5b
top_k: 6
max_context_chunks: 4
chunk_max_chars: 900
use_vector: false # Switch retrieval mode
3.5 Core Code: Service Entry Point
app = FastAPI(title='asset-local-rag')
@app.post('/ask')
def ask(req: AskRequest):
hits = retrieve(req.question, req.top_k or TOP_K)
answer = call_ollama(req.question, hits)
return {'answer': answer, 'citations': hits}
3.6 Core Code: Unified Retrieval Entry
def retrieve(query: str, top_k: int):
if USE_VECTOR:
return retrieve_vector(query, top_k) # Chroma vectors
else:
return retrieve_bm25(query, top_k) # BM25
BM25 retrieval: uses rank_bm25 plus jieba tokenization. It performs well on domain-specific terms and does not require an embedding model.
Vector retrieval: enabled when use_vector: true. Ollama is used for embeddings, and the vectors are stored in Chroma.
3.7 Core Code: Prompt Assembly
def call_ollama(question: str, contexts: list):
context_text = '\n\n'.join([
f"[Source: {c['path']}]\n{c['text']}"
for c in contexts[:MAX_CONTEXT]
])
prompt = f"{PROMPT}\n\nKnowledge Passages:\n{context_text}\n\nUser Question: {question}"
resp = requests.post(f'{OLLAMA_URL}/api/generate',
json={'model': OLLAMA_MODEL, 'prompt': prompt})
return resp.json()['response'].strip()
Key design choice: pass at most 4 chunks into the LLM, and label each chunk with its source.
3.8 Index Construction
python3 build_index_v2.py
build_index_v2.py reads all markdown files, splits them by # headings, filters meaningless fragments and Markdown noise, and outputs index.json.
3.9 Startup and Validation
python3 app.py
# Health check
curl http://127.0.0.1:8787/health
# RAG QA test
curl -X POST http://127.0.0.1:8787/ask \
-H "Content-Type: application/json" \
-d '{"question": "How do you calculate the D0 collection-entry rate?"}'
Chapter 4: Knowledge Base Construction
4.1 Design Principles
The knowledge base is the “brain” of the RAG system, and its quality directly determines retrieval quality. I follow three principles:
- Clear boundaries: the first version only covers asset-data-related content
- Layered structure: organize content by “definitions → dimensions → data dictionary → analysis SOP”
- Consistent format: use uniform Markdown, and give each concept its own
#heading
4.2 Directory Structure
asset_knowledge_base/
├── 01_metric_definitions/metric_dictionary.md # Metric definitions and formulas
├── 02_dimension_definitions/dimension_dictionary.md # Channels, customer segments, packages, etc.
├── 03_data_dictionary/asset_data.md # Asset data field descriptions
└── 04_analysis_sop/ # Analysis approaches for lower disbursement, worsening first delinquency, worsening spread, etc.
The layering serves different purposes: the definition layer explains “what it is,” the data layer explains “what fields exist,” and the application layer explains “how to use it.”
4.3 Markdown Writing Guidelines
Give each concept its own # heading so it does not get split across different chunks:
## D0 Order Collection Entry Rate
Definition: the share of orders that remain unpaid on the due date.
Formula: D0 order collection entry = 1 - dpd0_repay / dpd0_cnt
Avoid writing pure bullet lists. Each list item should include explanatory text.
4.4 Defining Knowledge Boundaries
| Can Answer | Cannot Answer |
|---|---|
| Disbursement scale, average amount per case, collection-entry rate, spread | Approval rate, approval workflow |
| Definitions of channels, packages, and customer segments | Collection strategy |
| Metric definitions and data field explanations | operation_data |
Boundary control is implemented in the prompt layer. The knowledge base itself does not need special handling.
4.5 Maintenance Workflow
Organize markdown files → commit to asset_knowledge_base/ → run build_index_v2.py → service picks up changes automatically
Chapter 5: Chunking Strategy Iteration
5.1 Why Chunking Matters
Chunking is one of the easiest parts of RAG to underestimate, even though it has an outsized effect. Chunk quality directly determines whether retrieved content is complete.
5.2 v1: Heading-Based Splits Plus Hard Character Limits
Split on # headings. If a section is within 900 characters, keep it as a single chunk; if it is longer, split it further by accumulating paragraphs.
Problems exposed by v1:
| Problem | Symptom | Impact |
|---|---|---|
| Heading-only fragments | A heading like # Secondary Heading becomes a chunk even with no body text |
Retrieval returns empty content |
| Markdown noise | List markers and numbering interfere with embeddings | Vector quality drops |
| Broken context | Definitions and formulas get split apart | Retrieved content is incomplete |
5.3 v2: Filtering Plus Cleanup
Before building the index, filter meaningless fragments such as text under 40 characters or chunks where heading lines exceed 70%, and clean Markdown noise such as list markers, numbering, and code markers.
def is_meaningful_chunk(text: str) -> bool:
if len(stripped) < 40: return False
if title_lines / len(lines) > 0.7: return False
return True
5.4 Reflection
Even with v2, a hardcoded 900-character split still has limitations. Formulas and explanations may end up in different chunks, tables can get broken apart, and cross-section references can fail. v2 is a practical answer under resource constraints, not the optimal one.
Chapter 6: Retrieval Pipeline Design
6.1 BM25 Retrieval
BM25 is a sparse retrieval algorithm and can be understood as an upgraded TF-IDF: tokenize the query, calculate TF, introduce IDF to penalize common words, and normalize for document length.
Strengths: no embedding model required, runs locally, and performs well on domain-specific terms such as “D0 collection entry” or “average amount per case.”
Weaknesses: it only matches literal wording, so synonyms such as “average amount per case” versus “average contract amount” cannot be recalled well.
6.2 Vector Retrieval
Switch it on or off through use_vector: true/false in config.yaml. Ollama handles embedding generation, and Chroma stores the vectors.
Downside: it requires an extra embedding model and vector database. In practice, it ran slowly on a 2 vCPU / 3.8 GB machine.
6.3 Unified Retrieval Entry
def retrieve(query: str, top_k: int):
if USE_VECTOR:
return retrieve_vector(query, top_k)
else:
return retrieve_bm25(query, top_k)
Both modes are switched through configuration and are transparent to upper layers.
6.4 Example Retrieval Result
{
"id": "01_metric_definitions/metric_dictionary.md#3",
"path": "01_metric_definitions/metric_dictionary.md",
"text": "## D0 Order Collection Entry\n\nDefinition: still unpaid on the due date...\nFormula: D0 order collection entry = 1 - dpd0_repay / dpd0_cnt",
"score": 8.67
}
score is the BM25 relevance score and can be used as a confidence signal.
Chapter 7: Prompt Engineering and Safety Constraints
7.1 System Prompt Design
Prompt design determines whether the model behaves the way you expect. I follow three principles:
- Whitelist the scope: explicitly list what topics can be answered
- Blacklist refusal cases: explicitly list out-of-scope domains and standard refusal language
- Constrain uncertainty: if evidence is insufficient, the model must not invent an answer and should say “I don’t know”
7.2 My Prompt
You are the local RAG QA model for the asset agent.
Strict rules:
- You may answer only based on the provided knowledge passages
- You may answer only within the first-version scope of nigeria_asset.asset_data
- For questions about approval rate, collection execution, or other out-of-scope topics, you must answer: "The current knowledge base does not support this question"
- Do not fabricate fields, definitions, or conclusions
7.3 User Prompt Assembly
context_text = '\n\n'.join([
f"[Source: {c['path']}]\n{c['text']}"
for c in contexts[:MAX_CONTEXT] # At most 4 chunks
])
prompt = f"{PROMPT}\n\nKnowledge Passages:\n{context_text}\n\nUser Question: {question}"
Key design choice: MAX_CONTEXT = 4 avoids exceeding the model’s context limit, and each chunk includes a source label for traceability.
7.4 Boundary Test Results
| Question | Expected Behavior | Actual |
|---|---|---|
| “How do you calculate D0 collection entry?” | Answer from the metric dictionary | ✅ |
| “What was this week’s approval rate?” | “Not supported by the knowledge base” | ✅ |
| “Which orders are overdue?” | Refuse and say database lookup is required | ✅ |
Chapter 8: Evaluation Results and Bottleneck Analysis
8.1 Subjective Score: 6 / 10
| Dimension | Score | Notes |
|---|---|---|
| Retrieval recall | 6/10 | Weak synonym recall |
| Generation quality | 5/10 | The 0.5B model has limited understanding |
| Response speed | 8/10 | Local inference, no network latency |
| Stability | 7/10 | Occasional OOM under tight resources |
| Explainability | 8/10 | Clear sources, good traceability |
The two biggest weaknesses are the model is too small and synonym recall is weak.
8.2 Bottleneck 1: The Model Is Too Small
qwen2.5:0.5b struggles with more complex reasoning, such as multi-step calculation questions. It also sometimes misinterprets analytical terms such as “week-over-week” and “year-over-year,” and instruction following is not fully stable.
8.3 Bottleneck 2: Low Retrieval Recall
BM25 performs literal matching only, which leads to issues like:
- “Average contract amount” does not recall “average amount per case”
- “First delinquency rate” does not match “first-delinquency deterioration”
- Conversational phrasing does not align with the formal wording in the knowledge base
8.4 Bottleneck 3: No Reranking
Current pipeline: query → BM25 top_k → LLM
Ideal pipeline: query → BM25 top_20 → Rerank top_4 → LLM
A two-stage retrieval pipeline would significantly improve relevance, but current machine resources do not support it.
Chapter 9: Pitfalls and Lessons Learned
Pitfall 1: OOM Due to Unrealistic Resource Assumptions
I originally tried vector retrieval with qwen2.5:3b, and 3.8 GB of RAM was immediately exhausted. The fix was to downgrade to qwen2.5:0.5b and disable vector retrieval, using BM25 only.
Lesson: do not overestimate hardware. Start by getting the smallest viable setup running.
Pitfall 2: Chunk Size Was Too Coarse
In the early version, I used 1500-character chunks, which split “definition + formula + notes” into three pieces, so retrieval often came back incomplete. The fix was to reduce the chunk size to 900 characters and require the knowledge base to follow a “one concept, one paragraph” writing style.
Lesson: chunking strategy and knowledge-base writing guidelines need to be optimized together.
Pitfall 3: Prompt Injection
If the user entered something like “Ignore the previous rules,” the model could skip constraints. The fix was to add a “strict rules” section in the system prompt and filter inputs in the application layer.
Lesson: small local models do not follow instructions as reliably as larger models. You cannot assume prompt constraints are naturally effective.
Pitfall 4: Ollama Hot-Reload Issues
When switching use_vector, if Ollama was not started cleanly, the service would return HTTP 500 errors without crashing, which made debugging harder. The fix was to add a /health endpoint for active status checks.
Chapter 10: Optimization Directions and Closing Thoughts
10.1 Model Upgrade Path
qwen2.5:0.5b (current)
↓ Upgrade first when memory allows
qwen2.5:3b (+2 points)
↓ Add more RAM / GPU when possible
qwen2.5:7b (+3 points)
↓ Further upgrade
LLaMA3.1:8B / ChatGLM4:9B
10.2 Two-Stage Retrieval Plan
candidates = retrieve_bm25(query, top_k=20) # Stage 1: coarse ranking
reranked = cross_encoder_rerank(query, candidates, top_k=4) # Stage 2: reranking
Expected benefit: a 15% to 20% improvement in recall.
10.3 Synonym Expansion
QUERY_EXPANSIONS = {
"average amount per case": ["average contract amount", "average borrowed amount per person"],
"collection entry": ["overdue", "unpaid", "non-performing"],
}
10.4 Summary
This RAG system is not a “perfect solution.” It is the best compromise under current resource constraints:
- 2 vCPU / 3.8 GB / no GPU → BM25 + 0.5B is the only realistic option
- It is usable, but the bottlenecks are obvious → a score of 6 is a starting point, not an ending point
- Every iteration is about doing the most worthwhile thing the current resource budget allows
The core engineering principle is this: there is no universally optimal solution, only the solution that best fits the current stage.